RKNN 硬件特性概览
来源:RK3588 TRM Chapter 36 RKNN
RKNN 是专用于神经网络的处理单元,旨在加速人工智能(AI)领域的神经网络运算,涵盖机器视觉和自然语言处理等方向。AI 的应用范围正在不断扩大,目前已在多个领域提供功能支持,包括人脸追踪、手势与肢体追踪、图像分类、视频监控、自动语音识别(ASR)以及高级驾驶辅助系统(ADAS)。
核心特性
| 特性 | 说明 |
|---|---|
| 核心数量 | 三核 NPU(Triple NPU CORE) |
| 协作模式 | 支持三核协同、双核协同、单核独立工作 |
| 配置接口 | AHB 接口,仅用于寄存器配置(单次访问) |
| 数据接口 | AXI 接口,用于从内存取数据 |
| 内部缓冲 | 384KB × 3(每核 384KB) |
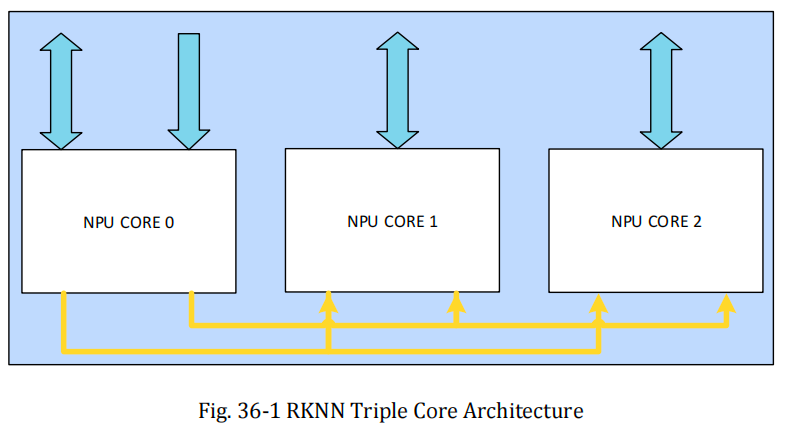
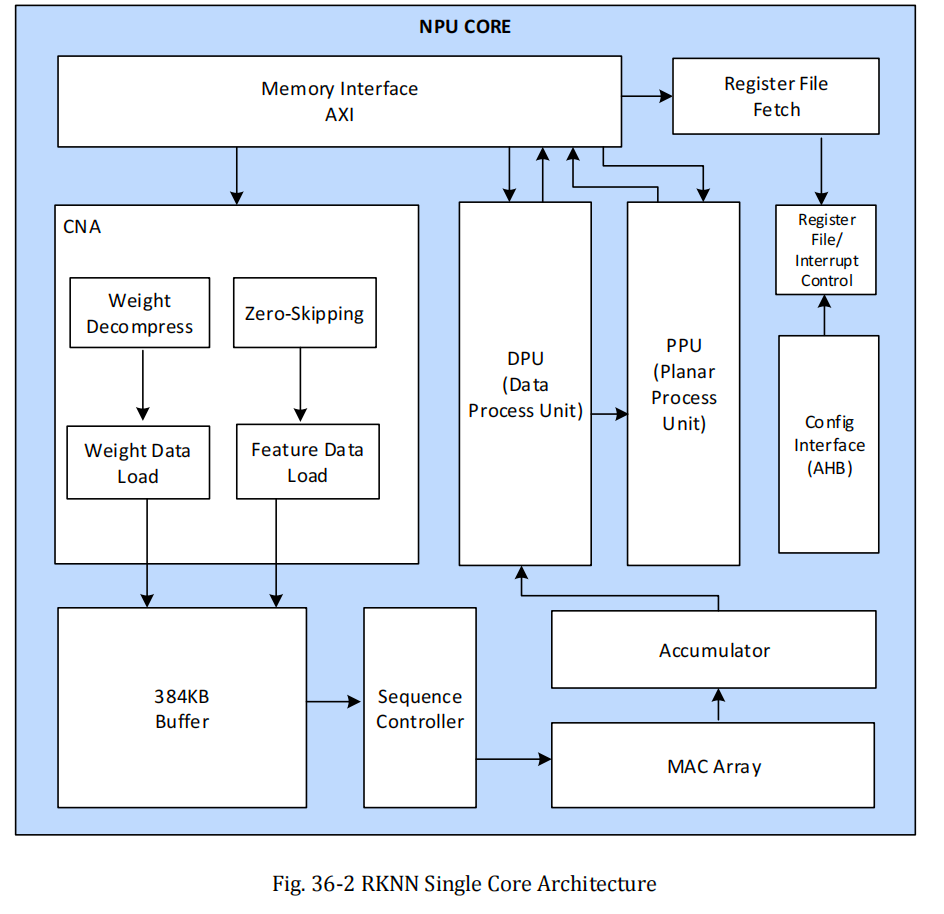
功能模块描述
AHB / AXI 接口
AXI 主接口用于从挂载在 SoC AXI 互联总线上的内存中取数据。AHB 从接口用于访问寄存器,进行配置、调试和测试。
神经网络加速引擎(Neural Network Accelerating Engine)
该引擎是神经网络运算的核心处理单元,包含卷积预处理控制器、内部缓冲区、MAC 阵列和累加器。它为识别功能提供并行卷积 MAC 运算,支持 INT4、INT8、INT16、FP16、BF16 和 TF32 数据类型。
数据处理单元(Data Processing Unit, DPU)
数据处理单元主要负责单数据运算,如 Leaky ReLU、ReLU、ReLUx、Sigmoid、Tanh 等激活函数。同时提供 Softmax、转置(Transpose)、数据格式转换等功能。
平面处理单元(Planar Processing Unit, PPU)
平面处理单元在数据处理单元输出之后执行平面操作,支持平均池化(Average Pooling)、最大池化(Max Pooling)、最小池化(Min Pooling)等。
寄存器配置取数单元(Register File Fetch Unit, PC)
寄存器配置取数单元通过 AXI 接口从外部系统内存中获取寄存器配置(即命令流),实现硬件自动配置各功能模块寄存器。
支持的数据精度与算力
| 数据类型 | 每周期 MAC 操作数(三核合计) |
|---|---|
| INT4 | 2048 × 3 = 6144 |
| INT8 | 1024 × 3 = 3072 |
| INT16 | 512 × 3 = 1536 |
| FP16 | 512 × 3 = 1536 |
| BF16 | 512 × 3 = 1536 |
| TF32 | 256 × 3 = 768 |
支持的推理框架
TensorFlow、Caffe、TFLite、PyTorch、ONNX NN、Android NN 等。