这个Pages展示本项目的开发计划和项目文档
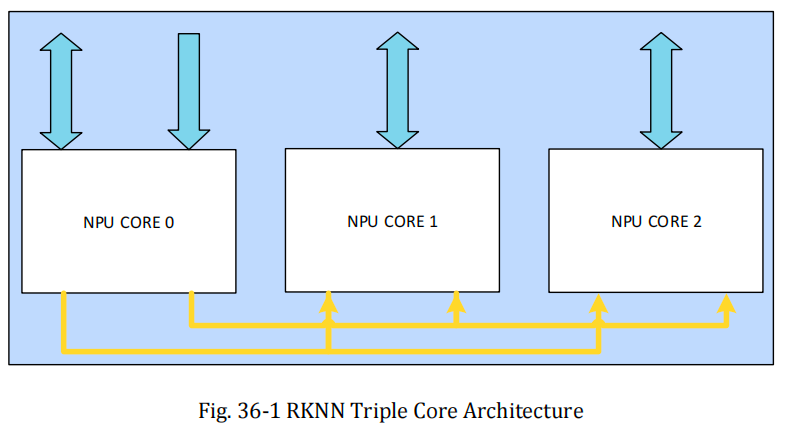
RK3588 NPU 驱动开发路线图
进度总览
当前状态:电源域管理 (Power Domain) 目标:将添加了npu驱动的starry编译拷贝到开发板验证探测
实际计划
第一阶段:环境验证与基础初始化
1. 理论与环境准备
-
阅读手册与 Demo
- 研读 RK3588 技术参考手册中 NPU 章节。
- 分析 RKNN Toolkit2 的官方 Demo,理解从模型加载到推理的完整数据流
-
实体机环境验证 (基于 StarryOS 比赛版)
- 编译并烧录比赛版本的 StarryOS 代码到 RK3588 实体板。
- 成功运行一个简单的文本生成模型,确保硬件和工具链正常。
-
整理 StarryOS 对 RK3588 NPU 驱动的逆向成果
-
寄存器地图
- 按模块梳理:PC / CORE / CNA / DPU / PPU / SDMA / DDMA / GLOBAL
- 对每个寄存器记录:offset、字段含义、读写属性、默认值/复位值、关联流程
- 标注来源:TRM / Linux rknpu 驱动
-
提交协议与数据结构
-
整理
DRM_IOCTL_RKNPU_*ioctl 列表与语义(Action / MemCreate / MemMap / MemDestroy / MemSync / Submit) -
对齐结构体布局:
rknpu_mem_create/rknpu_mem_map/rknpu_task/rknpu_submit(字段意义与对齐) -
梳理
mmap(offset)规则(handle 与 offset 的编码/解码约定)
-
整理
-
任务提交流程(时序 + 状态机)
- 从“用户态提交”到“硬件执行完成”的完整时序
- 失败路径:超时、异常中断状态、非法参数
-
寄存器地图
第二阶段:异步推理支持
目标:将当前同步阻塞轮询的任务提交改为中断驱动的异步模式,提交任务后 CPU 不再空转等待,NPU 完成后通过中断通知。
实现情况
- 中断处理 — 实现 IRQ 驱动模式,CPU 通过 WFI 指令进入低功耗等待,NPU 完成后触发中断唤醒 CPU
-
异步等待机制 — 实现
wait_all_npucore函数,支持多核心并行等待,每个核心独立触发中断 -
并发安全 — 每个核心维护独立的
irq_status原子变量,避免多核并发访问冲突 - 超时与错误恢复 — 实现中断状态检查和错误传播机制,异常时正确上报错误码
第三阶段:NPU多任务并发运行
目标:支持多个NPU计算任务同时在NPU多核上进行
实现情况
-
硬件资源隔离 — 验证 3 个 NPU 核心的 PC/CORE/CNA 等寄存器 per-core 独立,GLOBAL 寄存器通过
core_idx参数隔离 - GEM 内存隔离 — 实现 per-core 的 regcmd 缓冲区分配,每个核心使用独立的 DMA 地址空间
-
核心分配策略 — 实现
subcore_task机制,支持灵活的核心分配,QKV 三核并行、Wo 单核等混合调度
项目日志
记录 RKNN NPU 驱动开发进展。
RKNPU技术报告
一、项目内容与用途
这个项目的对象是 RK3588 NPU 驱动及其在 StarryOS 上的系统集成。它的作用:让上层推理程序、benchmark 或后续 runtime 能稳定地把任务提交给 NPU 执行,而不是只能依赖 Linux 或闭源用户态库环境。
当前驱动已经覆盖了几条基础链路:
- 寄存器/MMIO 访问:能够映射 RK3588 RKNPU 三个 core 的寄存器窗口,并通过寄存器接口完成 PC、CNA、DPU 等硬件模块的配置。
- GEM/DMA 缓冲管理:支持用户态创建、映射、同步和销毁 NPU 可访问的 DMA buffer。
- 任务描述符组织:支持
RknpuTask、regcmd、输入/权重/输出 buffer 的组合,并把这些描述符作为 submit 的基本执行单元。 - ioctl 服务:支持
Submit、MemCreate、MemMap、MemDestroy、MemSync、Action等 RKNPU 专用入口。 - 中断与 completion 回收:IRQ handler 负责读取硬件完成状态,调度器再根据 core 绑定关系把 completion 还原到具体任务。
- 多核调度:在一个 submit 中按 lane 把任务切到不同 core,同时支持多个 submit 进入队列等待。
二、本轮二次开发重点
2.1 支持 RK3588 三核 NPU 执行
RK3588 的 RKNPU 不是单个执行核心,而是三个可以并行工作的 NPU core。早期单核路径只证明了“任务能跑”,但没有把硬件并行能力发挥出来。本轮二次开发首先把提交路径改成能够识别 core_mask 和 subcore_task,让同一批任务可以被拆成多个 lane 分发到不同 core。
当前的三核执行模型可以概括为:
- 用户态仍然通过一个
RknpuSubmit提交任务批次。 subcore_task[]描述每个 lane 的任务范围;如果用户态没有显式填写 lane,队列层会把任务归一化到默认 lane。core_mask决定这次 submit 允许使用哪些物理 core,例如0x1表示只用 core0,0x7表示三个 core 都可用。- 调度器为每个空闲 core 挑选一个可派发 lane,然后调用底层 driver 对该 core 编程。
- core 完成后,IRQ 路径发布 raw completion,调度器再回收并推进对应 lane 的 cursor。
这部分工作的重点不是简单把同一条命令发三遍,而是要保证每个 core 跑的是正确的 task slice,同一条 lane 不会被重复派发,completion 也能回到正确的 submit 和 task index。只有这些状态对齐,多核数据才有意义。
2.2 任务调度器与多线程共享 NPU
第二个是任务调度器。NPU 是共享硬件资源,不能让多个线程各自直接碰寄存器,否则很容易出现 core 状态、任务进度和 completion 归属混乱。当前实现保留外部的 blocking submit 语义,但内部引入了调度队列和 worker 线程:
- 调用线程进入
Submitioctl 后,不直接独占 NPU 跑完整批任务,而是把 submit 放进 scheduler。 - 每个 submit 有自己的 waiter。调用线程只等待“自己的 submit 是否完成”。
- 全局 worker 负责真正的 dispatch 和 harvest。它被 kick 唤醒后,先回收已完成 core,再给空闲 core 下发新任务。
- scheduler 维护 ready、running、complete 这些状态。ready 表示还没开始跑的 submit,running 表示已有 lane 在跑或还有 lane 可继续派发,complete 表示终态结果等待 ioctl 路径取回。
- 如果 running submit 还有可派发 lane,会优先继续推进 running,而不是马上切到一个全新的 ready submit。这样可以减少同一 submit 内部的等待空洞。
service 层的 blocking submit 通过 per-submit waiter 阻塞:调用线程在 wait_for_submit() 上等待,直到 worker 将该 submit 移入 complete 并调用 waiter.complete() 唤醒它,再通过 take_terminal_submit() 取回终态结果。多个用户线程同时提交 NPU 任务时,线程可以各自阻塞在自己的 waiter 上,NPU 由全局 worker 串行管理硬件状态并并行利用多个 core。换句话说,NPU 对外看起来仍是阻塞式设备,对内已经具备”多线程共享、队列化提交、三核流式执行”的基础形态。
这版调度器的价值就在这里:它没有把用户态 ABI 改复杂,但把内核侧的执行模型从"谁提交谁跑"推进到了"统一排队、统一分发、统一回收"。
2.3 引入 rknpu-regs 寄存器库
寄存器访问层也做了工程化整理,引入了基于 SVD / svd2rust 生成的 drivers/rknpu-regs。驱动开发里手写寄存器偏移和位域非常容易出错,尤其是 NPU 这种寄存器块多、字段分散、不同 core 地址重复的硬件。
rknpu-regs:
- 用类型化寄存器接口替代裸地址和 magic number。
- 减少手工抄写偏移、位宽、mask 时的错误。
- 让寄存器访问代码更接近硬件文档,后续查错更方便。
- 把”访问寄存器”和”调度策略”拆开,避免调度器里混入大量底层地址细节。
三、benchmark 测试内容
3.1 测量范围与方法
本次性能数据来自 log.txt 中运行的 ./core_scaling_benchmark,对应测试程序是 core_scaling_benchmark.c。
测量窗口:仅覆盖 blocking DRM_IOCTL_RKNPU_SUBMIT 的完整往返时间,即 submit ioctl 从进入到返回。operand packing 和 regcmd generation 单独打印,不计入对比窗口。因此下面的数据反映的是 driver submit、scheduler dispatch/harvest、硬件执行和 completion 回收的综合耗时
指标定义:
speedup = T_1core / T_3core(同一批任务 1-core 与 3-core 的平均 submit 时间之比)parallel efficiency = speedup / 3(理想三核加速为 3x,efficiency 衡量实际利用率)GFLOP/s = 2 × GMAC/s(1 MAC = 1 乘 + 1 加 = 2 FLOP)jitter span = (T_max - T_min) / T_avg(衡量单次 submit 时间的波动幅度)
正确性校验:第一轮 measured round 会对输出抽样与 CPU reference 比较,并检查每个 task 的 int_status == 0x300。这是抽样校验,不是全量验证。
3.2 测试环境
- 硬件平台:RK3588 SoC(三核 NPU)
- 操作系统:StarryOS比赛版本
- Benchmark 程序:
core_scaling_benchmark(4 场景 × 2 operand 模式) - 测量轮次:每场景 warmup 2 轮 + measured 5-12 轮(场景相关)
- 频率/电源控制:未控制(默认 governor)
- 热稳态控制:未控制
- IRQ 亲和性:未设置
3.3 测试场景
每个场景一般又分两种 operand 模式:
shared-operands:所有任务复用同一份 input/weight,只有 output slice 私有。这更偏向测试调度和计算本身,DMA footprint 较小。unique-operands:每个 task 有自己的 input/weight/output slice。这更接近多任务独立数据的情况,内存占用和准备成本更高。
测试程序里固定了四个场景。它们不是随便取的矩阵形状,而是分别压不同瓶颈:
| 场景 | 矩阵形状 | shared tasks | unique tasks | warmup | measured | 主要验证点 |
|---|---|---|---|---|---|---|
tiny_dispatch | M=4 K=32 N=16 | 96 | 96 | 2 | 12 | 小矩阵,submit/scheduler 固定开销占比最高,用来观察多核调度在短任务下是否会被开销吞掉。 |
mid_balanced | M=64 K=512 N=512 | 48 | 12 | 2 | 8 | 中等矩阵,调度开销和计算吞吐都会影响结果,用来判断调度器是否进入稳定可用区间。 |
throughput_heavy | M=128 K=1024 N=1024 | 24 | 4 | 2 | 5 | 大矩阵,目标是把瓶颈推向 NPU 计算吞吐;unique 任务数较少,是为了控制 DMA footprint。 |
llama_decode_like | M=1 K=4096 N=4096 | 48 | 0 | 2 | 8 | 低 M、高 K、高 N,接近 LLM decode 阶段线性层投影形状,更关注长任务延迟和尾部波动。 |
tiny_dispatch 主要看调度器的“底噪”。如果这个场景三核退化,说明每次 dispatch、IRQ 回收、worker yield、waiter 唤醒的成本已经压过了硬件并行收益。它使用 96 个 task,任务数足够多,可以持续给三个 core 喂任务,但单 task 计算量非常小。
mid_balanced 是更接近日常 benchmark 的中间档。shared 模式有 48 个 task,unique 模式只有 12 个 task,因为 unique 模式每个 task 都有独立 input/weight/output,内存占用增长更快。这个场景用来观察调度器在“既有计算量、又有一定任务数量”的情况下是否稳定。
throughput_heavy 则故意把矩阵放大。shared 模式有 24 个 task,unique 模式只有 4 个 task。这里不是为了追求任务数,而是为了让每个 task 本身足够重,看三核并行能否把 GFLOP/s 拉上去。unique 任务数少也会暴露另一个问题:当任务批次太短时,三核并行窗口会变窄。
llama_decode_like 只跑 shared 模式,unique tasks 在测试程序里设为 0,所以日志里会跳过 unique。它模拟的是 decode 阶段常见的投影类 workload:M 很低,但 K 和 N 很大。这个场景不一定追求最高吞吐,更关心一次 submit 的阻塞时间能不能被多核明显压下来。
输入和权重不是随机数,而是由 deterministic_input_value() 和 deterministic_weight_value() 生成的整数模式;输出会抽样和 CPU reference 比较。每个 task 的 int_status 也会检查,期望值是 0x300。任务分发时,distribute_tasks_to_cores() 会按 core 数把 task range 平均切到 subcore_task[],1 core 时只填 core0,3 cores 时填 core0/core1/core2 并设置对应 core_mask。因此这个 benchmark 测到的不是单纯的 C 程序循环,而是完整覆盖了 submit ABI、调度器 lane 切分、三核 dispatch、IRQ completion 和 copy-back 这些路径。
四、benchmark 结果与性能分析
4.1 总体结论
所有有效场景里,三核都比单核快,没有出现最终退化。最好的场景是 llama_decode_like/shared-operands,从 344.354 ms 降到 137.000 ms,speedup 达到 2.514x,parallel efficiency 为 83.78%。这说明调度器已经能把 RK3588 三个 NPU core 的并行能力用起来。
三核都有正收益,但大多数场景的 parallel efficiency 仍在 57% 到 68% 左右
4.2 结果汇总
| 场景 | 模式 | 任务数 | 1-core avg submit | 3-core avg submit | speedup | parallel efficiency |
|---|---|---|---|---|---|---|
tiny_dispatch | shared | 96 | 2.533 ms | 1.423 ms | 1.780x | 59.32% |
tiny_dispatch | unique | 96 | 3.478 ms | 1.739 ms | 2.000x | 66.67% |
mid_balanced | shared | 48 | 32.496 ms | 18.746 ms | 1.733x | 57.78% |
mid_balanced | unique | 12 | 10.459 ms | 6.065 ms | 1.724x | 57.48% |
throughput_heavy | shared | 24 | 42.656 ms | 20.864 ms | 2.044x | 68.15% |
throughput_heavy | unique | 4 | 6.781 ms | 3.939 ms | 1.721x | 57.38% |
llama_decode_like | shared | 48 | 344.354 ms | 137.000 ms | 2.514x | 83.78% |
4.3 tiny_dispatch:小任务也有明显收益
tiny_dispatch 的矩阵规模很小,单 task 的计算量低。当前结果里,shared 模式从 2.533 ms 降到 1.423 ms,unique 模式从 3.478 ms 降到 1.739 ms。这说明当前调度器的固定开销没有大到完全吞掉三核收益,小任务也能加速。
但是这个场景的性能不能过度解读。shared 模式 parallel efficiency 是 59.32%,unique 模式是 66.67%,距离理想三核加速2x以上仍有明显差距。小任务下,每次 dispatch 和 completion 的成本占比很高,真正花在矩阵计算上的时间太短。后续如果要优化小任务,需要减少每 task 的下发/回收成本,或者把更多小 task 合并成更粗粒度的 batch。
4.4 mid_balanced:中等任务证明调度器进入显著加速区间
mid_balanced 是这次比较有代表性的场景。shared 模式中,1 core 平均 submit 为 32.496 ms,3 core 为 18.746 ms,speedup 为 1.733x。unique 模式中,1 core 为 10.459 ms,3 core 为 6.065 ms,speedup 为 1.724x。
这个结果说明,调度器在中等任务规模下已经进入稳定可用区间。两种 operand 模式都接近 1.7x,没有只在某一种特殊数据复用方式下才有效。它也说明当前瓶颈不只是数据准备,因为 benchmark 的 measured window 没把 operand packing 算进去;submit 阶段本身确实因为多核并行缩短了。
4.5 throughput_heavy:吞吐型任务收益更明显
throughput_heavy 的 shared 模式从 42.656 ms 降到 20.864 ms,speedup 达到 2.044x,parallel efficiency 为 68.15%。同时 GFLOP/s 从 151.033 提升到 308.786,基本也是 2.044x 的增益。这个场景最能说明三核调度的直接价值:任务足够重之后,固定调度开销被摊薄,硬件并行执行开始成为主导因素。
unique 模式任务数只有 4 个,这是为了控制 DMA footprint。它仍然从 6.781 ms 降到 3.939 ms,speedup 为 1.721x。任务数少会限制三核利用率,因为 worker 能同时派发的 lane 数量和后续补发机会都变少。这个结果没有 shared 模式好,但仍然是稳定正收益。
4.6 llama_decode_like:长任务场景收益最好,但 jitter 较大
llama_decode_like 是本次最强的结果。它的 shared 模式从 344.354 ms 降到 137.000 ms,speedup 达到 2.514x,parallel efficiency 为 83.78%,GFLOP/s 从 4.677 提升到 11.756。这说明在低 M、高 K、高 N 的投影类 workload 下,当前三核调度能显著降低 submit 阻塞时间。
但这个场景也反应出在3-core 的 min/max 为 126.027 / 139.504 ms时,jitter span 达到 9.84%,明显高于 1-core 的 0.03%。也就是说,平均值很好,但三核路径下仍有一定波动。可能原因包括 worker harvest 时机、core completion 到达顺序、yield 后重新调度的时间差,以及更长任务下不同 core 之间的尾部等待。
4.7 这轮结果说明
- 三核支持已经有效。所有有效 benchmark 场景都显示 3-core submit 时间低于 1-core。
- 调度器设计已在真实 benchmark 中转化为性能收益。ready/running 队列推进、core binding 和 completion 回收这套机制能够有效利用三核并行。需要注意的是,当前 benchmark 验证的是单次 blocking submit 内的多核扩展收益,而非多线程并发提交的竞争场景——后者是调度器设计支持的能力,但尚未专项测试。
- 软件开销仍然存在。大多数场景没有接近理想
3x,说明 dispatch、harvest、同步和调度唤醒成本仍然需要优化。
五、功能模块分层与实现思想
当前实现可以按从上到下的链路理解。
最上层是用户态 benchmark 或 runtime。它负责准备输入、权重、输出、regcmd 和 task array,然后通过 ioctl 提交任务。benchmark 还负责构造不同矩阵规模和不同 operand 共享模式,用来观察调度器在不同负载下的行为。
再往下是 ioctl / service 边界层。它负责把用户态传进来的 RknpuSubmit、RknpuTask[] 和内存管理请求拷入内核,转换成驱动内部可以处理的数据。这里不应该保存太多调度状态,否则 ioctl 层会变成第二个 scheduler。
scheduler 层负责 submit 生命周期。它维护 ready、running、complete 三个 bucket,管理每个 submit 的 waiter,也负责唤醒全局 worker。waiter 和 kick 的职责要分清:waiter 是 per-submit 的,回答"这个 submit 完成了吗";kick 是全局 worker 信号,回答"现在有没有新活需要 worker 醒来处理"。这两个东西混在一起,调度器会很难读,也很容易漏唤醒。
driver / dispatch / IRQ 层负责硬件事实。driver 给某个 core 编程,IRQ handler 读取和清除硬件中断,completion 只表示"某个 core 有原始完成状态"。至于这个 completion 属于哪个 submit、哪个 lane、哪个 task index,应由 scheduler 根据 core_binding 还原,而不是让 driver 反向保存一堆队列语义。
最底层是寄存器访问层,也就是 rknpu-regs。它提供类型化 register API。调度器不应该知道太多寄存器细节,寄存器层也不应该知道队列策略。这个分层让后续工作可以分开推进:寄存器访问继续补全,调度策略继续优化,ioctl ABI 保持稳定。
六、当前限制与问题分析
- 三核收益仍然低于理想值。除了
llama_decode_like达到83.78%efficiency,多数场景仍在57%到68%左右。说明当前并行并不是完全线性扩展,软件路径还有明显成本。 - 小任务场景仍然敏感。
tiny_dispatch虽然这次有正收益,但它的绝对 submit 时间只有毫秒级,任何一次额外调度、yield、IRQ 回收或锁竞争都会改变结果。后续如果要跑大量小算子,必须继续压低固定开销。 - 3-core 路径存在尾延迟波动。
llama_decode_like的平均 speedup 很好,但 3-core jitter span 到了9.84%。这提示我们不能只盯 avg submit,还要看 min/max 和尾延迟。
七、调度器的执行时序
本节描述调度器的内部机制和执行流程,内容基于 drivers/rknpu/src/service/scheduler.rs 和 drivers/rknpu/src/task/taskqueen.rs 的实现。
7.1 核心数据结构
NpuSchedulerState(调度器全局状态,受单一 mutex 保护):
tasks: BTreeMap<RknpuQueueTaskId, RknpuQueueTask>— 所有活跃 submit 的唯一所有者ready: BTreeMap<i32, VecDeque<RknpuQueueTaskId>>— 按优先级分桶,尚未开始执行的 submitrunning: BTreeMap<i32, VecDeque<RknpuQueueTaskId>>— 按优先级分桶,已有 lane 在执行或还有 lane 可派发的 submitcomplete: BTreeMap<RknpuQueueTaskId, RknpuQueueTask>— 已终态,等待 ioctl 路径取回core_binding: BTreeMap<usize, CoreRunBinding>— 物理 core →{task_id, lane_slot, task_index}的归属映射waiters: BTreeMap<RknpuQueueTaskId, Arc<W>>— per-submit 的阻塞等待器
RknpuQueueTask(单个 submit 的运行时状态):
lane_isrun: [bool; 5]— 每条 lane 是否有任务在飞subcore_cursors: [u32; 5]— 每条 lane 已完成的 task 数量last_error: Option<RknpuError>— 错误状态
submit 的生命周期状态(ready/running/complete)不是单独维护的枚举,而是由 lane_isrun、subcore_cursors、last_error 的组合派生,并通过 reclassify_task() 决定 submit 应归入哪个 bucket。
7.2 调度策略
running-before-ready:dispatch_idle_cores() 为每个空闲 core 选择候选时,优先从 running bucket 中找可继续派发的 submit(prepare_dispatch_from_running),只有当没有 running submit 可用时,才从 ready 提升新 submit(promote_ready_and_prepare_dispatch)。这减少了同一 submit 内部的等待空洞,但对等待中的 ready submit 不是严格公平的。
内存同步边界:
comfirm_write_all():在一次dispatch_idle_cores()调用中,对某个 submit 首次派发前调用,确保 DMA 写入对硬件可见prepare_read_all():在 terminal submit 唤醒 waiter 前调用,确保硬件写回对 CPU 可见
7.3 图一:Submit 生命周期
注意:函数签名可能随着更新而改变实际函数签名以代码仓库中为准,此处只做流程解读
下图展示单个 submit 从 ioctl 入队到 copy-back 返回的完整路径,以及多个并发 submit 线程如何通过独立 waiter 共享同一个 worker。

7.4 图二:Worker 主循环与多核派发
注意:函数签名可能随着更新而改变实际函数签名以代码仓库中为准,此处只做流程解读
下图展示 worker 线程的主循环结构,以及 harvest 和 dispatch 如何交替推进多个 submit 的执行。

相关仓库
驱动主仓库
StarryOS与驱动的桥接层
演示视频
PPT
第一周开发日志(1.25-1.31)
工作总结
- 基础知识学习 — 学习 NPU 原理、AI 模型运行原理、驱动在整个推理链条中的角色
- RKNN Toolkit2 仿真验证 — 下载套件,阅读 demo 代码,在 x86 仿真器上跑通测例
基础知识学习
刚接到 NPU 驱动开发任务时,虽然听说过 NPU,但对它实际是什么、解决什么问题、工作原理、如何运行都不了解。花了一天时间系统学习了以下内容:
- NPU 是什么 — 神经网络处理单元,专为矩阵运算和推理加速设计的硬件
- AI 模型的本质 — 本质上是一个函数,是大量矩阵乘法配上激活函数。训练是拟合参数,推理是执行前向传播
- 模型格式与转换 — ONNX → RKNN 格式转换,量化,以及模型在 NPU 上的执行流程
- 驱动在整个链条中的角色 — 用户态库(
librknnrt.so)通过 ioctl 与内核驱动通信,驱动负责任务调度、DMA 搬运、寄存器操作
RKNN Toolkit2 套件与仿真验证
上 Rockchip 官网下载了 rknn-toolkit2 套件,发现里面包含一个 仿真器,可以在 x86 主机上模拟 RKNPU 的部分功能。阅读了 demo 代码,理解了 RKNN 推理的基本 API 调用流程:
rknn_init()来初始化npu执行上下文 → rknn_inputs_set()读写npu寄存器设置输出输出参数 → rknn_run()写npu寄存器提醒npu开始工作和运行 → rknn_outputs_get()npu通过中断通知操作系统,用户库从约定位置读取结果 → rknn_destroy()销毁释放npu执行上下文
第二周开发日志(2.1-2.7)
工作总结
- 开发板验证通过 — 在 OrangePi 5 Plus(RK3588)上部署 StarryOS(NPU 版本),成功跑通 RKNN 推理测例
- 闭源库逆向文档整理 — 整理了
librknnrt.so逆向成果、完整寄存器语义、模型推理全链条,发布至 GitHub Pages - 驱动骨架搭建 — 创建
axnpu-rknn独立 crate,编写 DTB 设备探测代码,通过rdrive框架自动匹配 NPU 设备 - DRM 框架初步实现 — 创建
axdrmcrate,实现 GEM 内存对象管理和 ioctl 编码解析与分发机制
开发板验证
搭载 RK3588 芯片的 OrangePi 5 Plus 开发板到了之后,将带有 NPU 支持的 StarryOS 版本(atomgit 仓库)部署到开发板上,成功跑通测例,验证了 NPU 驱动在 StarryOS 上的可行性。
闭源库逆向与文档整理
花了 3 天时间系统整理了以下内容:
librknnrt.so闭源库逆向成果 — 梳理了用户态库的内部调用流程、ioctl 命令、内存管理机制- 寄存器语义 — 从官方 TRM 手册和 RKNN 开源内核驱动(C 语言版本)中,整理了完整的寄存器描述和语义
- 模型推理全链条 — 从
rknn_init到rknn_destroy的完整生命周期,包括任务提交流程、状态机、DMA Fence 路径等
文档链接:https://qc-gpu-driver.github.io/starryos-pulsar/documents/docs.html
这份文档不仅方便自己开发时查阅,也相当于一份社区参考文档,我也会一直维护和验证的,方便更多对 RKNN NPU 驱动感兴趣的开发者查阅和使用。
驱动骨架编写
最初尝试直接在 arceos/modules/ 下创建 axnpu-rknn 驱动模块,但遇到了 workspace 循环依赖问题——ArceOS 的 axdriver_block 锁定的版本缺少 ahci feature,而 Cargo workspace 会全量解析所有 members 的依赖,导致整个 workspace 编译失败。
参考 StarryOS(NPU 版本)的做法,将驱动模块移动到 Starry 根目录下独立开发,等完善后再集成回 arceos。
编写了 dtbparse.rs,利用 ArceOS 的 rdrive 框架通过设备树(DTB)自动探测 NPU 设备:
#![allow(unused)] fn main() { module_driver! { name: "RKNPU", level: ProbeLevel::PostKernel, priority: ProbePriority::DEFAULT, probe_kinds: &[ ProbeKind::Fdt { compatibles: &["rockchip,rk3588-rknn"], on_probe: probe_rknpu } ], } fn probe_rknpu(info: FdtInfo<'_>, dev: PlatformDevice) -> Result<(), OnProbeError> { let name = info.node.name(); // 提取 MMIO 基址: 0xfdab0000, 大小: 0x9000 let mut regs = info.node.reg().ok_or_else(|| { /* ... */ })?; let base_reg = regs.next().ok_or_else(|| { /* ... */ })?; let mmio_base = base_reg.address as usize; let mmio_size = base_reg.size.unwrap_or(0x9000); // 提取中断号: SPI 110, 111, 112(3 个 NPU 核心) // ... Ok(()) } }
module_driver! 宏会将驱动自动注册到 rdrive 框架,内核启动时遍历 DTB,匹配 compatible = "rockchip,rk3588-rknn" 后自动调用 probe_rknpu,无需手动调用。
DRM 框架搭建
创建了 driver/axdrm crate,作为用户态接口适配层:
GEM 内存对象管理 — 实现了 GemNumberAllocator(handle 编号分配/回收)、GemObject(物理地址、虚拟地址、fake offset)、GemHandle(自动回收的 RAII handle)
ioctl 编码解析 — 实现了 DRM ioctl 命令的解码函数:
| 函数 | 作用 |
|---|---|
ioctl_nr(cmd) | 提取 ioctl 编号(bits [7:0]) |
ioctl_type(cmd) | 提取类型字节(DRM = 'd' = 0x64) |
ioctl_size(cmd) | 提取参数大小(bits [29:16]) |
is_driver_ioctl(cmd) | 判断是否为驱动私有命令(nr >= 0x40) |
ioctl 分发机制 — 驱动通过 register_driver() 注册自己的 ioctl handler,dispatch_ioctl() 根据命令编号自动分发到对应驱动。NPU 驱动只需注册一个回调函数即可处理私有 ioctl。
第三周开发日志(2.8-2.14)
工作总结
- 修复 Axvisor 上 rsext4 文件系统导致的磁盘数据不一致问题 — 客户机写文件后重启出现 "block is free" 错误,定位为 rsext4 缓存未同步,在写操作后增加
sync_to_disk调用修复 - svd2rust 寄存器库重构 — 基于 svd2rust 工具生成类型安全的寄存器访问库,重构 rknpu 驱动核心,减少手动操作寄存器的出错概率
- 辅助注释与文档 — 利用 AI 为驱动代码添加详细注释,兼顾学习与开发效率
- 基于 WFI 的异步中断处理 — 实现了 NPU 中断的异步等待机制
修复 Axvisor 上 rsext4 文件系统磁盘数据不一致问题
问题
- 客户机执行文件写操作后重启,出现
block is free(双重释放,原来没有正确把1写回位图) (位图实际扫描使用的Block和超级块中的Block不一致)错误,磁盘数据损坏 - 如果启动的是 Linux 客户机,Linux 在启动过程中会因文件系统完整性校验失败而无法启动
分析
Linux 客户机的问题是由于 Axvisor 在启动客户机的最后时刻调用 mount_virtual_fs 时没有刷新文件系统,导致文件系统不一致。Linux 启动时进行文件系统完整性校验,发现不一致后拒绝启动,随后关机导致缓存丢失,最终造成文件系统损坏。
根源在于 rsext4 为提升运行时性能设计了多级缓存机制,但 Axvisor 在集成 rsext4 时,没有在文件写操作后进行数据同步。如果客户机修改文件后立即关机,缓存仍停留在内存中,不可避免地导致磁盘数据不一致。
解决方案
在 rsext4 的 ext4fs.rs 访问层中,对所有写操作调用 sync_to_disk 函数,确保数据及时同步到磁盘。虽然会带来一定的性能损失,但保证了文件系统的一致性。
开发板环境踩坑
本周在板端遇到了一系列棘手的环境问题,花了不少时间排查:
U-Boot 与启动链问题
- U-Boot 缺少网卡驱动 — 板载 U-Boot 不支持网络传输,只能通过串口
loady加载内核,debug 内核每次都要通过串口传内核很慢,每次修改都需要完整烧录StarryOS内核 - SPI 残留环境变量 — 从 OrangePi 官方 Ubuntu 镜像中提取干净的 U-Boot,制作 SPI 镜像刷入开发板。但刷完后发现 SPI 中残留了旧的 U-Boot 环境变量,导致启动失败,只能重新刷回 SPI 镜像
- eMMC 与 SD 卡混淆 — StarryOS 在开发板上扫描到板载 eMMC,但驱动却强制探测 SD 卡。起初误以为使用的是 SD 卡,经分析后确认实际使用的是板载 eMMC
后续 NPU 驱动工作开发路线决策
最初尝试将 NPU 驱动集成到 StarryOS 主线,但 HAL 层架构 axhal 与 somehal 存在冲突,RK3588 平台级代码集成涉及整个架构的大修改。为专注于 NPU 驱动核心功能开发,决定先在 StarryOS NPU 版本上开发,待主要功能完成后再移植回主线。
svd2rust 寄存器库重构
基于 svd2rust 工具重构 rknpu 驱动的寄存器访问层。
#![allow(unused)] fn main() { // 旧方式:手动偏移 + 裸指针 let status = unsafe { ptr.add(0x20).read_volatile() }; }
改进
通过 svd2rust 从 SVD 描述文件生成类型安全的寄存器库 rknpu-regs,每个寄存器字段都有明确的类型和文档:
#![allow(unused)] fn main() { // 新方式:类型安全 + 自动补全 + 文档 let status = core.pc().interrupt_status().read().bits(); core.pc().interrupt_clear().write(|w| unsafe { w.bits(INT_CLEAR_ALL) }); }
成果
- 生成了完整的寄存器定义,覆盖 PC、CNA、CORE、DPU、PPU、DDMA 等所有功能块
RknpuCore结构体封装了各功能块的访问方法,提供统一接口- 编译期类型检查杜绝了寄存器偏移量写错、位域宽度搞混等常见错误
AI 辅助注释
利用 AI 为 axnpu 驱动代码添加了详细的中文注释(关键函数的调用流程和参数说明)
既方便自己学习 NPU 硬件细节,也降低了后续开发和他人协作的门槛。
基于 WFI 的异步中断处理
实现了 NPU 任务完成的异步等待机制:
- NPU 核心执行完任务后触发中断
- CPU 通过 WFI(Wait For Interrupt)指令进入低功耗等待状态
- 中断到来时 CPU 被唤醒,读取中断状态寄存器,清除中断标志
- 返回任务执行结果
这为后续多核并发任务提交打下了基础——每个 NPU 核心可以独立触发中断,CPU 侧可以并行等待多个核心的完成通知。
第五周开发日志(2.22-2.28)
工作总结
- RK3588 NPU 三核并行矩阵乘法实现 — 扩展 Transformer 结构体支持 3 套 regcmd 缓冲区,实现
matmul_npu_3core_qkv函数,将 QKV 三个矩阵乘法并行提交到 3 个 NPU 核心,板端验证推理成功 - 驱动多核提交流程重构 — 修改
submit_ioctrl实现批量任务分配,支持一次 ioctl 向多个核心提交任务,新增wait_all_npucore并行等待机制
验证结果
板端运行日志显示多核并行成功:
[261.640936] Total tasks to submit: 3, active cores: 3, max batch size: 4095
[261.650710] Total tasks to submit: 1, active cores: 1, max batch size: 4095
[262.295035] Total tasks to submit: 3, active cores: 3, max batch size: 4095
...
Once upon a time...
3 tasks, 3 cores表示 QKV 三核并行成功1 tasks, 1 core表示后续的wo矩阵乘法(单核)- 模型推理输出 "Once upon a time..." 验证结果正确
驱动多核提交流程重构
批量任务分配
重构 submit_ioctrl 函数,支持将用户空间的任务数组自动分配到多个 NPU 核心:
#![allow(unused)] fn main() { pub fn submit_ioctrl(&mut self, args: &mut RknpuSubmit) -> Result<(), RknpuError> { // 1. 刷新缓存,确保 NPU 能看到 CPU 写入的数据 self.gem.comfirm_write_all()?; // 2. 提取活跃的核心任务 let active_subcore: Vec<&RknpuSubcoreTask> = args.subcore_task.iter() .filter(|s| s.task_number > 0).collect(); // 3. 批量提交到多个核心 while task_iter < task_iter_end { let task_batch = active_subcore.len().min(task_iter_end - task_iter); let submit_tasks = unsafe { core::slice::from_raw_parts_mut(task_ptr.add(task_iter), task_batch) }; // 并行启动每个核心的任务 for idx in 0..active_subcore.len().min(task_batch) { self.base[idx].start_execute_one(idx, &self.data, &mut submit_tasks[idx], args)?; } // 并行等待所有核心完成 self.wait_all_npucore(self.wait_fn, int_mask, submit_tasks)?; task_iter += task_batch; } // 4. 使缓存无效,确保 CPU 能读取 NPU 写入的结果 self.gem.prepare_read_all()?; Ok(()) } }
并行等待机制
新增 wait_all_npucore 函数,实现多核心并行等待:
#![allow(unused)] fn main() { pub fn wait_all_npucore(&self, normal_wait_fn: Option<fn()>, int_mask: Vec<u32>, submit_tasks: &mut [RknpuTask]) -> Result<(), RknpuError> { let mut done: [bool; 3] = [false; 3]; if let Some(wait) = normal_wait_fn { // IRQ+WFI 模式:CPU 休眠等待中断 loop { let status: Vec<u32> = self.base.iter() .map(|core| core.irq_status.load(Ordering::Acquire)).collect(); // 检查每个核心的完成状态 for idx in 0..submit_tasks.len() { if status[idx] & int_mask[idx] > 0 { self.base[idx].clean_interrupts(); self.base[idx].irq_status.store(0, Ordering::Release); submit_tasks[idx].int_status = int_mask[idx] & status[idx]; done[idx] = true; } } // 所有核心都完成则退出 if done[..submit_tasks.len()].iter().filter(|&d| !d).count() == 0 { break; } // CPU 进入低功耗等待 (wait)(); } } else { panic!("[NPU] busy-poll mode not implemented for multi-core wait"); } Ok(()) } }
第六周开发日志(3.1-3.7)
工作总结
-
NPU驱动移植到主线 — 将比赛版本上的 NPU 驱动和 aarch64 动态平台配置成功移植到 StarryOS 主线版本,系统启动成功,NPU 三核中断注册成功。不足:eMMC 驱动初始化失败导致系统崩溃,需要进一步排查;
-
WFI 异步调度优化 — 将 WFI 函数替换为 yield 函数,实现真正的异步调度,NPU 工作时 CPU 可以执行其他任务,提升系统并发性能 不足:异步调度目前仅实现单核版本,SMP 完整实现仍在主线版本中
第七周开发日志(3.8-3.14)
-
工作进展:本周主要做的是规划,无实习任务相关的实质性代码工作
-
本周做出了对下周工作的详细规划以及个人对aarch64的详细学习
-规划如下:
NPU 协处理器化架构设计 (NPU as FPU)
1. 概述
本项目提出并实现一种创新的异构计算架构,旨在将 NPU 从传统的、基于 VFS/ioctl 的“设备”模型,提升为与 CPU 核心紧耦合的“协处理器”。其设计目标是通过极致的软硬件协同,实现 NPU 算力调度
2. 核心设计哲学
彻底废弃传统基于 VFS(虚拟文件系统)和 ioctl 的松耦合设备驱动模型。将 NPU 提升为与 CPU 平级的计算协处理器(类比 FPU 浮点运算单元)。通过共享 DMA 内存、定制化系统调用(Syscall)与“懒汉式”上下文切换(Lazy Context Switch)实现算力调度。
3. 内核数据结构扩展 (TCB 升级)
为了让操作系统的调度器(Scheduler)能够接管 NPU 资源,必须扩展内核的任务控制块(TCB / task_struct):
-
npu_isdirty: bool- 含义:NPU 硬件上下文“脏”标识位。
true:表示当前物理 NPU 硬件的内部 SRAM 和寄存器中,依然保留着该任务的数据和状态。false:表示该任务的 NPU 状态已被换出,或者尚未使用过 NPU。
-
npu_context: struct- 含义:NPU 硬件上下文结构体。追加在原生 CPU 任务上下文之后。
- 作用:用于存储 NPU 被强行打断或切换时的完整硬件状态机。需查阅具体 NPU 芯片的闭源驱动源码及手册,提取并保存完整的寄存器集合(如命令队列指针、当前算子偏移量、中断屏蔽字等)。
4. 用户态基础框架 (libnpu)
在用户层封装底层细节,向应用程序开发者提供极简的 C/C++ 接口。
-
专属内存分配 (
dma_malloc系统调用)- 抛弃标准
malloc。用户通过dma_malloc直接向内核申请一段物理地址连续的 DMA 内存。 - 目的:绕过 IOMMU 的复杂页表配置,让 NPU 硬件的 DMA 控制器可以直接通过物理地址(PA)高速拉取数据。
- 抛弃标准
-
强制中断注入
- 用户将计算参数、模型权重写入申请好的 DMA 内存区域。
- 在构建 NPU 任务描述符(Task Descriptor)链表时,
libnpu会在底层介入,将每个微小可配置算子任务结构体中的中断控制位(IRQ Enable)强制设为开启。这是后续内核能够精准捕获算子边界、实现状态保存的关键。
-
内联汇编触发 (
npu_workAPI)- 利用 AArch64 调用约定,将装载了任务描述符链表的 DMA 内存物理地址指针塞入约定的寄存器(如 X0)。
- 执行定制的内联汇编(包含特定的
SVC陷入指令),直接触发定制的resolve_npu系统调用。
5. 内核态调度核心 (resolve_npu 系统调用)
这是整个架构的调度心脏。当 CPU 通过 SVC 陷入内核态后,严格按照以下流水线执行:
阶段 1:内存转换与前置检查
- 地址翻译:将 X0 寄存器传入的用户态虚拟地址(VA),通过查询页表或 DMA 分配记录,转换为 NPU 硬件所需的物理地址(PA)。
- 硬件状态机检查:检查全局 NPU 硬件状态(
IDLE或BUSY)。
阶段 2:懒汉式上下文切换 (Lazy Context Switch) 调度器需要仲裁当前物理 NPU 硬件的归属权。
- 碰撞检测:检查系统中是否存在一个“前任任务”,其
npu_isdirty == true,且该任务并非当前请求任务。 - 等待安全边界:如果存在这样的“前任任务”(说明 NPU 硬件中存有他人数据),内核绝不能强行复位硬件。必须检查 NPU 当前是否为
IDLE。如果是BUSY,当前 CPU 线程必须挂起睡眠(加入等待队列),直到 NPU 算完当前算子并触发硬件中断。 - 保存前任状态:当 NPU 确认处于
IDLE后,内核立刻将 NPU 硬件内的全量寄存器状态抽取出来,保存到那个“前任任务”的npu_context中。 - 剥夺前任所有权:将“前任任务”的
npu_isdirty标志位修改为false。
阶段 3:恢复当前状态并启动硬件
- 检查当前记录:检查当前请求任务的 TCB 中,是否存有尚未跑完的
npu_context(即之前被切换出去的状态)。 - 状态恢复:如果存在,则将
npu_context里的数据原封不动地写回 NPU 的物理控制寄存器。 - 宣誓主权:将当前任务的
npu_isdirty标志位置为true。 - 硬件启动 (Kick the Doorbell):将阶段1中转换好的任务描述符物理地址指针,写入 NPU 的“任务执行寄存器”,并写入特定的启动命令(“踢门铃”)。
- 状态标记与返回:将全局 NPU 状态标记为
BUSY,CPU 退出系统调用,返回用户态继续执行或调度其他普通线程。
6. 硬件中断处理程序 (NPU IRQ Handler)
由于 libnpu 强制开启了每个算子的中断,NPU 每算完一个微小算子就会发出硬件 IRQ。
- 进入 ISR:CPU 陷入内核中断服务例程。
- 确认完成:读取 NPU 硬件状态寄存器,确认当前算子计算完成。
- 释放路权:将全局 NPU 状态强制标记为
IDLE(空闲)。 - 唤醒等待者:唤醒在
resolve_npu系统调用中,因为 NPUBUSY而挂起睡眠的其他任务线程,让它们得以重新参与 NPU 的抢占与上下文切换流程。
第八周开发日志(3.15-3.21)
工作总结
- 阶段性代码提交 — 本周完成一次阶段性代码提交
1d4e8fe,核心是把rknpu提交路径收敛为“单 task 边界步进 + 外层调度器轮转推进”,并补齐最小 DMA syscall 与用户态试验链路。提交链接:Commit - NPU 提交路径支持单 task 边界切换 — 驱动只保留
submit_ioctrl_step_with_owner()这条步进入口,在每个 task 完成 IRQ 边界返回,让多个进程可以轮流推进各自未完成的 submit - DMA syscall 与用户态辅助库打通 — 保留
sys_dma_malloc、sys_dma_free和对应轻量用户态封装,用于板端分配与释放 DMA 缓冲区 - 新增多进程/混合工作负载验证 — 新增
matmul_multi_process与matmul_llama_concurrent两个测试程序,板端验证多进程交错提交和 llama 推理并发场景 - 寄存器级保存/恢复路径彻底下线 — 当前主线不再保留完整寄存器快照、恢复镜像、毒值写坏和读回校验逻辑,IRQ 路径只更新最小 owner/task 状态
单 task 边界调度改造
本周核心工作是把原来“一次 ioctl 一口气跑完整批任务”的同步提交逻辑,改造成“每次只推进一个当前 task-batch,完成后返回调度器”的步进式路径。
当前驱动只保留两类最小状态:
NpuOwnerIds— 由外层调度器提供的 owner 标识,使用“线程 ID + 进程 ID + 地址空间指针”唯一标定一次 submit 的归属- 每核 owner 槽位 — 每个硬件 core 只保留一个
NpuOwnerState,记录该 core 当前绑定的 owner、当前 task、task 指针、task 索引,以及最近一次 IRQ 的观测结果
不再保留:
- resident owner
- owner 级 submit/context 快照
(owner, core)共享状态表- 完整寄存器保存/恢复镜像
新的路径大致如下:
card1在进入RKNPU_SUBMIT时,用“当前线程 ID + 当前进程 ID + 当前地址空间指针”组装 owner- 驱动执行
submit_ioctrl_step_with_owner(),本次最多只推进一个 task-batch - 每个参与的 core 在下发前先绑定一个最小
NpuOwnerState - 每个核心收到预期完成中断后,驱动更新对应 task 的
int_status,同步回写 owner 槽位里的 IRQ 字段,然后立即清空该 core 槽位 - 如果整次 submit 还没结束,就
yield_now()主动让出,允许别的 owner 进来推进它自己的 submit - 下次同一个 owner 再进来时,只根据
task_counter从上次稳定完成的位置继续
这样之后,进程级切换点就固定在了“单个 task 完成 IRQ 边界”上,而不是“整个 submit 全部完成”之后。
板端验证已经可以观察到这种交错推进:
[NPU] batch done: int_status=0x300
...
matmul_multi_process: pass
这说明当前已经不是“一个进程一次性独占跑完整次 submit”,而是由外层 loop 在 task 边界轮流推进多个 owner。
多进程与混合负载测试
为了验证当前这套“单 task 边界切换”不是只在单个 demo 里自娱自乐,本周新增了两个更贴近真实使用方式的测试程序。
1. matmul_multi_process
这个测试会同时启动 4 个子进程。每个子进程只发起 1 次 submit,但这次 submit 里串了 20 个相关联的 matmul task:
- task 0 的输出作为 task 1 的输入
- task 1 的输出再作为 task 2 的输入
- …
- 最终做逐 task、逐元素 CPU 参考校验
它验证的不是“多个短任务抢一个锁”,而是:
- 单个 submit 内还有剩余 task 时,驱动能否在 IRQ 边界切出去
- 之后切回来时,能否从正确的
task_counter继续推进 - 多个进程交错执行后,中间状态和最终输出是否仍然正确
最终板端结果为:
matmul_multi_process: pass
中断边界实验的收敛
本周原本也同步尝试了更激进的路线:在 IRQ 完成边界读取 live 寄存器快照,把准备恢复的寄存器先写入固定毒值,再按镜像恢复,最后读回校验。
但在板端验证时发现,至少有一部分 task-window 配置寄存器 在“任务刚完成、IRQ 已到达”的这个边界之后,并不保证还能按提交时的原值稳定读回。例如曾经观察到:
first_task_shadow_mismatch={ offset=0x100c, expected=0x120, got=0x0 }
first_task_shadow_mismatch={ offset=0x4058, expected=0xf, got=0x0 }
这说明两个事实:
- 当前边界对“task 已完成”是稳定的
- 但它不一定对“所有任务窗口寄存器还能按原值读回”稳定
因此当前版本做了一个更明确的收敛:
- 不再尝试保存/恢复整套寄存器镜像
- 不再保留毒值验证、恢复镜像、读回校验的主线逻辑
- IRQ 路径只保留“读取 live IRQ、清中断、更新最小 owner/task 槽位状态”
也就是说,当前主线解决的是“可运行、可验证、可继续扩展”的 task 粒度协作式调度基础设施;任意寄存器级/算子级抢占 不在本次提交范围内。
本周结论
本周最重要的进展,是把 单任务级边界(核 IRQ 中断边界)切换 + 多进程交错推进 + 结果正确 这一层跑通,并进一步把驱动内部状态压缩到了最小模型。
当前已经可以确认:
- 抢占/切换粒度已经从“整次 submit”下沉到了“单个 task 完成 IRQ 边界”
- 多个进程提交各自含有多 task 的 submit 时,驱动可以轮流推进
- 驱动内部不再承担 owner 上下文保存/恢复,也不再提供完整 NPU 状态导出接口
下一步的重点,是继续在当前 task 粒度调度稳定的基础上,围绕更细的调度与恢复能力评估真实可行的硬件边界,而不是继续维护一套过重的软件镜像模型。
第九周开发日志(3.22-3.29)
工作总结
本周的主要工作是实现一个基于 Clang front-end 的 RKNPU 代码生成工具。该工具面向“显式标注 + 代码生成”的使用模式:用户在 C 源码中对可加速代码段进行手工标注,工具负责识别被标注的算法结构,并将其转换为对应的 NPU 任务提交流程,从而把原本由 CPU 执行的计算卸载到 NPU 上。
当前版本已经完成从前端识别到代码生成的基础闭环,但支持范围仍较为有限,仅支持标准形态的 matmul 算子。
代码仓库
本周进展
- 完成了基于
Clang front-end的前端识别方案,可以对带有显式标记的 C 代码进行分析。 - 完成了标准矩阵乘法代码模式的识别与验证,能够从纯 CPU 风格实现中提取出可下沉到 NPU 的计算区域。
- 实现了面向 RKNPU 的基础代码生成流程,能够将识别后的
matmul区域转换为对应的 NPU 任务构造与提交流程。 - 建立了“手工标注 -> 识别分析 -> 代码生成”的最小闭环,为后续扩展更多算子和更复杂的调度机制打下基础。
遇到的问题与分析
本周原计划继续将 NPU 的任务调度粒度进一步细化到单个算子级别,以增加可调度时刻的数量,使单个进程占用 NPU 的最小时间片进一步缩小。
但在分析后发现,这一路径存在明显问题:如果将调度边界压缩到单个算子级别,将显著提高中断触发频率。虽然这样能够提升调度灵活性,但中断处理开销也会同步增大,整体性能收益并不理想,甚至可能得不偿失。
在此基础上,我进一步尝试思考和验证“任意时刻 checkpoint”方案,即在 NPU 运行过程中的任意时刻保存执行状态,并在之后恢复执行。当前主要遇到以下两个核心困难:
-
硬件层面缺少统一暂停机制
现有 RKNPU 硬件接口中,没有看到能够让多个功能部件在同一时刻一致性暂停的机制。因此,即使希望在某一时刻保存状态,也难以保证采集到的是一个全局一致、可恢复的硬件状态快照。
-
恢复执行难以做到无副作用
RKNPU 的启动方式本质上依赖于 PC 寄存器的启动脉冲。也就是说,恢复时并不是“从某个硬件内部断点继续执行”,而更接近一次重新触发执行。如果保存状态时任务正处于某个算子的执行过程中,那么恢复后很可能会导致该算子被重复执行,从而产生任务重放问题,破坏执行语义。
本周结论
本周完成了 RKNPU 代码生成工具链的第一版原型,实现了从 C 代码显式标注到 NPU 任务生成的基本流程,证明了“标准矩阵乘法代码经识别后自动生成 RKNPU 调用代码”这一方向是可行的。
第十周开发日志(3.30-4.5)
工作总结
本周的主要工作是完成 rknpu 任务调度器的正式落地。
这一周把提交、排队、分发、完成、唤醒这一整条路径实现了,让单次 submit 能在多核上并行推进,并在结束后正确返回到用户态。 提交链接
本周进展
- 完成了
rknpu调度器主路径的搭建,路径为card1 -> scheduler -> queue -> driver. - 保留阻塞式
submit,在内核内部为每次 submit 维护独立 waiter,使用户线程可以在提交后挂起等待,并在任务真正结束后被唤醒。 - 引入 worker 驱动的后台推进模型,通过全局
kick机制唤醒调度线程,避免提交线程自己承担全部硬件推进逻辑。 - 完成多核分发路径,支持把同一批任务按 lane 切分后投递到多个 core 上并行执行。
- 把队列层的职责收敛到“维护 ready submit、lane 游标和完成进度”这几个核心状态上,调度器负责选择可下发任务,驱动负责实际硬件提交和中断观测。
本周结论
本周已经完成 rknpu 任务调度器的主体实现。当前版本具备了完整的阻塞提交、后台 worker 推进、多核 lane 分发、terminal 唤醒能力。
第十一周开发日志(4.6-4.12)
工作总结
本周的工作进入了收尾阶段,围绕已经完成的 rknpu 调度器做最后测试、benchmark 验证
本周进展
- 完成了多轮 benchmark 测试,覆盖
tiny_dispatch、mid_balanced、throughput_heavy和llama_decode_like等场景,重点对比 1-core 与 3-core 的提交时间、吞吐和并行效率。 - 对调度器关键路径补充了更细的日志,覆盖 enqueue、worker 唤醒、dispatch、harvest、terminal wake 和 blocking wait 等节点。
遇到的问题与分析
本周最麻烦的问题,是 benchmark 过程中出现了偶发性的卡住或返回不稳定。
从现象上看,有些测试可以正常打印 benchmark complete status=0 并返回 shell;但也有一些运行过程中,会出现串口长时间停住、需要手动退出终端的情况。它并不是每次都能稳定复现。
结合当前benchmark日志,至少可以得到两个判断:
-
小任务场景下,多核并行并不一定带来正收益
在
tiny_dispatch这类尺寸很小的 workload 上,submit/scheduler 开销占比很高,3-core 的效率明显达不到理想值,甚至可能比 1-core 更慢。这说明当前瓶颈更多在调度与提交流程,而不是硬件算力本身。 -
中大型任务场景下,多核并行已经能稳定带来正收益
结合这轮 benchmark 记录,可以直接看到几组比较明确的结果:
mid_balanced场景下,1-core avg submit从56.158 ms降到39.204 ms,speedup = 1.432x,parallel efficiency = 47.75%throughput_heavy场景下,1-core avg submit从76.605 ms降到40.824 ms,speedup = 1.876x,parallel efficiency = 62.55%llama_decode_like场景下,1-core avg submit从423.358 ms降到231.858 ms,speedup = 1.826x,parallel efficiency = 60.86%
本周结论
本周完成了调度器收尾阶段最重要的一轮验证工作。当前版本已经能够支撑 benchmark 跑通,并能产出比较完整的日志和性能数据;
项目月报
2月技术报告-周雨
目标与问题
主要目标
- 阅读 RKNPU 驱动相关源码,学习 NPU/AI 相关知识,将 RKNPU 硬件手册总结为 markdown 文档
- 实现NPU驱动异步中断支持
- 实现NPU驱动多核多任务并发
主要问题
- 环境与工具链问题:开发板 U‑Boot 缺少网卡驱动,只能通过串口加载内核,调试效率低;U-boot网卡驱动编译困难,依赖太多,将会逐步解决
- 驱动集成冲突:尝试将 NPU 驱动集成到 StarryOS 主线时,HAL 层架构
axhal与somehal存在冲突,RK3588 平台级代码集成涉及整个架构的大修改。当前阶段将继续在当前已有驱动基础上开发。暂时不会集成到主线
方案或思路
面对上述问题,我制定了以下开发路线:
-
分阶段学习与验证:
- 第一阶段:学习 NPU 原理、AI 模型推理流程,利用 RKNN Toolkit2 仿真器在 x86 上验证推理链条。
- 第二阶段:在真实硬件(OrangePi 5 Plus RK3588)上部署 StarryOS(NPU 版本),验证驱动可行性。
- 第三阶段:逆向闭源用户态库
librknnrt.so,整理完整的寄存器语义和任务提交流程,形成社区参考文档。
-
驱动架构设计:
- 采用
rdrive框架实现设备树(DTB)自动探测,避免硬编码设备地址。 - 创建独立的
axdrmcrate 实现 DRM 框架,提供 GEM 内存管理和 ioctl 编码解析/分发机制,保持用户态接口兼容性。 - 将驱动模块放在 StarryOS 根目录独立开发,规避 workspace 循环依赖问题,待功能稳定后再集成回 ArceOS。
- 采用
-
寄存器访问安全:
- 使用
svd2rust工具从 SVD 描述文件生成类型安全的寄存器库rknpu-regs,覆盖 PC、CNA、CORE、DPU、PPU、DDMA 等所有功能块。 - 通过编译期类型检查杜绝寄存器偏移量写错、位域宽度混淆等错误。
- 使用
-
异步中断处理:
- 利用 WFI(Wait For Interrupt)指令实现低功耗等待,NPU 核心完成任务后触发中断,CPU 被唤醒并读取中断状态寄存器。
- 为后续多核并发任务提交奠定基础——每个 NPU 核心可独立触发中断,CPU 侧可并行等待多个核心的完成通知。
-
多核并发任务调度:
- 扩展驱动数据结构,支持多套寄存器命令缓冲区(regcmd)。
- 重构
submit_ioctrl函数,实现批量任务分配,一次 ioctl 可向多个核心提交任务。 - 新增
wait_all_npucore并行等待机制,循环检查各核心中断状态,直到所有核心完成任务。
-
问题规避与迂回:
- 暂时放弃将驱动集成到 StarryOS 主线,专注于在 NPU 版本上开发核心功能,减少架构冲突带来的干扰。
- 通过刷写干净的 SPI 镜像解决 U‑Boot 环境变量残留问题,明确使用 eMMC 作为存储介质。
实现情况
1. 基础知识学习与仿真验证(第一周)
- NPU 原理学习:理解了 NPU 作为神经网络处理单元的本质,掌握了 AI 模型训练与推理的基本流程,以及驱动在推理链条中的角色(用户态库通过 ioctl 与内核驱动通信,驱动负责任务调度、DMA 搬运、寄存器操作)。
- RKNN Toolkit2 仿真验证:在 x86 主机上利用 RKNN Toolkit2 的仿真器跑通测例,梳理出 RKNN 推理的 API 调用流程:
rknn_init→rknn_inputs_set→rknn_run→rknn_outputs_get→rknn_destroy。
2. 开发板验证与文档整理(第二周)
- 硬件验证:在 OrangePi 5 Plus(RK3588)开发板上成功部署 StarryOS(NPU 版本),并跑通 RKNN 推理测例,验证了 NPU 驱动在真实硬件上的可行性。
- 闭源库逆向与文档:系统逆向分析了
librknnrt.so用户态库,结合官方 TRM 手册和开源内核驱动,整理了完整的寄存器语义、任务提交流程、状态机与 DMA Fence 路径,形成 GitHub Pages 文档,为社区提供参考。
3. 驱动骨架与 DRM 框架搭建(第二周)
- 设备探测:编写
dtbparse.rs,利用rdrive框架通过设备树(DTB)自动探测 NPU 设备(compatible = "rockchip,rk3588-rknn"),提取 MMIO 基址(0xfdab0000,大小0x9000)和中断号(SPI 110‑112)。 - DRM 框架:创建
axdrmcrate,实现 GEM 内存对象管理(handle 分配/回收、物理地址映射)和 ioctl 编码解析/分发机制,为 NPU 驱动提供兼容 Linux DRM 的用户态接口。
4. 寄存器库重构与 AI 辅助注释(第三周)
- svd2rust 寄存器库:基于 SVD 描述文件生成类型安全的寄存器库
rknpu-regs,覆盖 PC、CNA、CORE、DPU、PPU、DDMA 等所有功能块。将原有的手动偏移+裸指针访问改为类型安全、带自动补全和文档的 API,例如:#![allow(unused)] fn main() { let status = core.pc().interrupt_status().read().bits(); core.pc().interrupt_clear().write(|w| unsafe { w.bits(INT_CLEAR_ALL) }); } - AI 辅助注释:利用 AI 为
axnpu驱动代码添加详细的中文注释,明确关键函数的调用流程和参数含义,降低后续开发和协作门槛。
5. 异步中断处理实现(第三周)
- WFI 等待机制:实现基于 WFI(Wait For Interrupt)指令的低功耗异步等待。NPU 核心完成任务后触发中断,CPU 进入休眠状态;中断到来时 CPU 被唤醒,读取中断状态寄存器并清除标志位,返回任务执行结果。
- 多核中断基础:该机制为多核并发任务提交打下基础,每个 NPU 核心可独立触发中断,CPU 侧可并行等待多个核心的完成通知。
6. 多核并行矩阵乘法实现(第五周)
- 三核并行 QKV 计算:扩展
Transformer结构体,支持 3 套 regcmd 缓冲区,实现matmul_npu_3core_qkv函数,将 Transformer 中的 Q、K、V 三个矩阵乘法并行提交到 3 个 NPU 核心。 - 批量任务分配:重构
submit_ioctrl函数,支持将用户空间的任务数组自动分配到多个 NPU 核心,一次 ioctl 可向多个核心提交任务。 - 并行等待机制:新增
wait_all_npucore函数,循环检查各核心中断状态,利用 WFI 等待所有核心完成,实现真正的多核并行等待。
7. 板端验证结果
板端运行日志显示多核并行成功:
[261.640936] Total tasks to submit: 3, active cores: 3, max batch size: 4095
[261.650710] Total tasks to submit: 1, active cores: 1, max batch size: 4095
[262.295035] Total tasks to submit: 3, active cores: 3, max batch size: 4095
...
Once upon a time...
3 tasks, 3 cores表示 QKV 三核并行成功。1 tasks, 1 core表示后续的wo矩阵乘法(单核)。- 模型推理输出 "Once upon a time..." 验证结果正确。
8. 其他问题修复(第三周)
- Axvisor 文件系统同步问题:修复了 rsext4 缓存未同步导致的磁盘数据不一致问题,在写操作后增加
sync_to_disk调用,确保文件系统一致性(PR #368)。
下一步的计划/建议
基于 1 月末和 2 月份的开发进展,后续工作可围绕以下方向展开:
-
驱动稳定性与健壮性
- 当前驱动还有很多unimpliment函数和特性,我将会继续完善它
- 完善错误处理机制,增强驱动健壮性
-
多核调度优化
- 实现动态负载均衡,根据各 NPU 核心的利用率自动分配任务。(当前多核并发是简单的任务切片)
- 支持任务优先级调度,确保高优先级任务优先执行。
- 探索任务依赖关系(DAG)支持,实现复杂模型层的流水线并行。
-
主线集成与代码重构
- 待 NPU 驱动功能稳定后,重新评估集成到 StarryOS 主线的可行性,解决 HAL 层冲突。
- 将
axnpu-rknn驱动模块迁移回 ArceOS 的modules/目录,遵循项目模块化规范。
-
文档与社区建设
- 持续更新 GitHub Pages 文档,补充更多寄存器细节、性能调优指南和故障排查案例。
3月技术报告-周雨
目标与问题
主要目标
- 将比赛版本中的 NPU 驱动和 aarch64 动态平台配置迁回 StarryOS 主线,先验证主线环境能不能真正承载 RKNPU 驱动,而不是一直停留在比赛分支上单独维护。
- 将原来一次性跑完整个 submit 的同步提交路径,改造成在 task 完成边界主动让出的协作式调度路径,让多个进程在共享 NPU 时有明确的切换点。
- 在驱动工作逐步稳定之后,继续往上层工具链推进,探索从带标注的 C 代码自动生成 RKNPU 调用代码,减少手工拼装任务描述符和提交流程的工作量。
主要问题
- 主线移植后虽然系统能够启动,NPU 三核中断也能注册成功,但目前平台适配层还有一些问题,实际调用 NPU 时会出现卡死。这个问题我还在继续排查,也说明主线环境离稳定开发还有一段距离。
- 更细粒度的调度与状态恢复并不只是软件设计问题。我在实验过程中已经明显碰到 RKNPU 的硬件边界。基于目前已经能稳定工作的单 task 粒度,我也认为没有必要继续追求任意时刻的调度,这件事现在看起来性能收益和工程收益都不大。
- 自动代码生成工具虽然已经跑通了 matmul 的最小闭环,但目前识别和生成能力都还非常有限
方案或思路
面对这些问题,我在 3 月的思路比 2 月更聚焦一些。2 月更多是在补驱动能力,3 月开始,我更在意这些能力能不能放回主线、能不能被调度,以及在确认硬件边界之后,哪些事情值得继续做,哪些事情应该及时收口。
-
将NPU驱动从比赛版本移植回主线
我是先把比赛版本上的 NPU 驱动和平台适配层移植回了主线,然后在实际使用NPU驱动时会导致系统卡死,目前问题正在排查中
-
从单线程任务独占改为多线程task step 协作式调度
3 月中期我花了一段时间重新想调度模型。当时我甚至考虑过把 NPU 做成类似 FPU 的协处理器,同时尽量把 ioctl 路径收得很薄。我往下做时,我是先把最重要的部分抽出来:不要再让一个 submit 一次性独占 NPU 到结束,而是把提交拆成 step,每次只推进一个当前 task-batch,在 IRQ 边界返回,由外层调度器决定谁继续。后面的工作重点也不是把切换做得越来越激进,而是继续把驱动层这套 task step 调度机制做扎实、做到能稳定的跑为止。
-
先用实验确认硬件边界,再主动收敛模型
我不想在还没确认硬件边界的时候,就先堆一套很重的软件上下文模型。所以 3 月里我专门对寄存器快照、恢复镜像、算子级中断和 checkpoint(也就是执行中途保存状态,之后再恢复继续跑)做了实验。实验结果如果不支持,我就直接暂时搁置这条路,而不是继续维护一套看起来完整、实际上很难跑通的设计,而且实验看来在如果要做到任意时刻打断和恢复的话必定需要NPU硬件本身支持checkpoint的一种恢复机制。现在看下来,在单 task 粒度已经能稳定切换的前提下,没有必要再把目标扩展到任意时刻调度,继续往那个方向做,开销会更高,收益却不明显。
-
向工具链上移,减少手工写驱动调用
到 3 月后半段,我开始把目光往上移,不再只盯着驱动内部。具体做法是基于 Clang front-end,也就是利用 Clang 编译器前端的语法分析能力,对带有显式标注的 C 代码做识别,然后尝试自动生成对应的 RKNPU 调用代码。第一步只做标准 matmul,先把最小闭环跑通。
实现情况
1. NPU驱动移植回 StarryOS 主线并完成基础验证
3 月一开始,我做的不是新功能,而是把比赛版本上的 NPU 驱动和 aarch64 动态平台配置迁回 StarryOS 主线。
实际验证结果比我预想得好一些。系统能够正常启动,NPU 三核中断注册也成功了。
问题:目前平台适配层还有一些问题,实际调用 NPU 时会出现卡死,具体原因我还在继续排查。
2. npu驱动中任务提交路径改造成单 task 边界协作式调度
这一部分是我 3 月最核心的工作。之前的模型很直接:一次 ioctl 进去,驱动把单个线程提交的整个 submit 从头跑到尾,跑完才返回。这样做实现起来不难,但问题也很明显,单个线程会长时间独占 NPU。只要 submit 足够长,别的线程就只能一直等。
我后来把这条路径改成了单步推进。具体做法是,在 card1 的提交路径里保留外层 loop + yield_now(),而驱动内部只保留 submit_ioctrl_step_with_owner() 这个 step 入口。这个函数每次最多只推进一个当前 task-batch,然后就在 task 完成后的 IRQ 边界返回。为了让它能重新进入,我把 task_counter 作为唯一恢复游标,下次进入时直接从上次稳定完成的位置继续算,不再另外维护一套复杂的快照。
驱动内部的状态也一起收窄了。每次 step 下发前,只给参与执行的 core 绑定一个最小的 owner/task 状态,用来记录“这个 core 当前在给谁跑哪个 task,以及最近看到了什么 IRQ”。任务完成后,驱动更新对应 task 的 int_status 和最近一次 IRQ 观测值,然后立刻把 core 槽位清掉。这样做的好处:切换点清楚,状态模型也足够小。
板端验证能说明这条路是通的。多进程 matmul_multi_process 和混合负载场景已经跑通,submit 不再是一家独占跑完,而是多个 owner 在 task 边界交错推进。这里的切换本质上还是协作式调度,不是任意时刻抢占。它解决的是多个线程怎么共享 NPU,不是怎么把 NPU 做成一个可以像 CPU/FPU 那样随时保存和恢复的通用协处理器。
3. NPU驱动更细粒度调度与状态恢复实验带来的收敛
我一开始其实想得更激进。我不满足于 task 边界调度,还想继续往下压,看看能不能做到更细粒度的切换,甚至尝试类似 checkpoint 的执行中途保存与恢复。为此,我在 IRQ 边界做过 live 寄存器快照、毒值写坏和恢复校验,也专门分析过算子级调度的可能性。
板端实验给出的反馈并不乐观。我当时观察到过这样的日志:
first_task_shadow_mismatch={ offset=0x100c, expected=0x120, got=0x0 }
first_task_shadow_mismatch={ offset=0x4058, expected=0xf, got=0x0 }
这说明一个很麻烦的问题:IRQ 虽然已经到了,task 也确实跑完了,但并不是所有 task-window 配置寄存器都会在这个边界上稳定地按提交值读回。也就是说,这个边界对“任务完成”是可靠的,对“完整寄存器状态可恢复”却不是。再往下走,如果把调度边界压到单个算子,中断频率会明显变高,灵活性是提高了,但中断和调度开销也会一起涨上来。更关键的是,当前硬件接口里我没有看到一个能让多个功能部件在同一时刻一致性暂停的机制,而恢复执行也不像 CPU/FPU 那样能从内部断点继续,更像重新触发一次执行,这就带来了任务重放的风险。
这些实验让我最后收敛得很明确:当前最稳妥的边界,仍然是 task 完成后的 IRQ 边界。所以 3 月我做出的判断不是完整寄存器保存/恢复写不下去,而是这条路在当前硬件边界下不值得继续当主线推进。再往任意时刻调度上做,软件会更复杂,中断和调度开销也会更高,但我现在看不到足够明显的收益。这也是为什么后来我把主线彻底收敛到了task 粒度协作式调度,并开始把精力放回驱动层任务调度本身的完善和优化。
4. 基于 Clang front-end 的 RKNPU 代码生成工具原型
3 月后半段,我开始结合ai工具做一个基于 Clang front-end 的 RKNPU 代码生成工具。这里的想法很直接:写纯cpu计算的代码,通过手工标注一段代码,让代码生成工具来进行中间的具体的NPU平台侧的代码生成和优化,这样我们我们不用写一行npu库相关的代码 而是让我们的代码生成工具来分析代码生成更优,性能更好的能跑在npu上的代码,这也是当时我想的最贴近让npu当作cpu的一个协处理器在软件层面的一个思路.
当前的做法是“显式标注 + 前端识别 + 代码生成”。用户先在 C 代码里标出可加速的区域,工具再利用 Clang front-end 对这些区域做语法级分析。目前我已经把标准形态的 matmul 识别跑通,并且能够把识别出的计算区域转换成对应的 RKNPU 任务构造与提交流程,形成一个最小闭环。代码仓库见 rknpu_gen。
当然,这一步离“通用自动生成”还差得很远。现在它能说明的,只是标准 matmul 这条链可以走通,不能说明复杂算子、复杂控制流或者更随意的代码风格也都能自动处理。但这一步还是很重要,因为它把我 3 月的工作从“让驱动能跑”往前推到了“让工具帮人用驱动”。这两个方向其实不是一回事。
下一步的计划/建议
- 继续排查和修复 StarryOS 主线下的平台适配问题,重点把当前“调用 NPU 会卡死”的原因定位清楚,让主线环境真正适合稳定调试。
- 在现有 task 边界协作式调度已经稳定的前提下,继续完善驱动层的任务调度和优化工作,把队列化、优先级和多任务推进模型做得更规范。
- 继续把多进程和混合工作负载测试做得更系统,确认当前 task step 调度在不同负载下的行为和开销,不再把任意时刻寄存器恢复作为当前主线目标。
- 最后做一个benchmark来验证我优化前后驱动性能的提升
4月技术报告-周雨
目标与问题
主要目标
- rknpu 任务调度器的正式落地:可以基于优先级调度处理多个线程提交的 submit。
- 驱动的工程化重构:将 RKNPU 驱动抽象为一个独立且通用的 Rust crates 库,外部 OS 通过实现驱动所需的 trait 来使用驱动,实现内核与驱动逻辑的解耦。
- 调度器性能验证:对完成的调度器进行全面的 Benchmark 验证,重点对比多核(3-core)与单核(1-core)在不同尺度 workload 下的提交时间与并行效率,产出完整的性能数据。
具体方案
1. 搭建后台 Worker 推进模型,解耦用户提交与调度器
为了避免用户线程长时间阻塞并承担硬件推进逻辑,我重新设计了提交流程:
- 后台 Worker 线程:设计了专门用于任务调度的 worker 线程。该线程在后台循环推进和调度任务。当没有任务时,worker 线程会进入两阶段睡眠(基于 listen 和 wait),挂起在监听新任务的信号量上;当有新任务入队时,通过全局的 notify_one (kick) 机制去唤醒调度线程。
- 用户态阻塞与唤醒:用户线程只需要调用 ioctl 接口将 NPU 任务入队即可睡眠等待。为此,我为每次 submit 维护了独立的 waiter(基于 RknpuSubmitWaiter trait)。用户线程在提交任务后直接挂起 (wait),直到任务在多核上真正结束并触发 terminal,再由底层调用 complete 唤醒用户线程,安全返回用户态。
2. 将 RKNPU 驱动抽象为通用 Crate
为了让 RKNPU 驱动不依赖于特定的 OS 环境(如 StarryOS),我在 crate 层设计了一套平台相关的 Trait 接口,外部 OS 只需要实现 RknpuPlatform 即可接入驱动。具体拆分如下:
- RknpuDeviceAccess:负责底层设备的临时可变借用(with_device),由 OS 决定低层级 RKNPU 实例的存储和锁机制。
- RknpuUserMemory:抽象了内核与用户态之间的内存拷贝操作(copy_from_user 和 copy_to_user),处理不同 OS 内存管理模型的差异。
- RknpuSchedulerRuntime:抽象了调度器所需的 OS 运行时能力,包括创建等待原语(new_waiter)、创建 Worker 唤醒信号(new_worker_signal)、生成后台 Worker 线程(spawn_worker)以及在硬件执行或调度停滞时的出让机制(yield_now)。
3. 多尺度 workload 的 Benchmark 测试
设计并执行覆盖多种场景的基准测试,包括:
- tiny_dispatch(极小任务调度)
- mid_balanced(中等规模平衡负载)
- throughput_heavy(重吞吐负载)
- llama_decode_like(模拟大模型解码负载)
实现结果
1. 调度模型与并发机制成功运行
成功实现了基于 Worker 线程和任务信号量的调度模型。底层通过 RknpuWorkerSignal 和 RknpuSubmitWaiter 实现了可靠的两阶段休眠与唤醒机制,彻底解决了用户态提交与底层硬件执行的深度耦合,多进程争抢 NPU 时的调度变得更加平滑。
2. 驱动 crate 化解耦完成
完成 rknpu crate 的重构,成功将平台强相关的内存拷贝、设备锁等待以及线程调度抽离到 RknpuPlatform trait 中。这证明了驱动的主体逻辑能够以纯库(Library)的形式独立演进,大幅提升了后续移植和维护的工程效率。
3. Benchmark 测试与多核性能验证
完成了全量 Benchmark 测试。结合日志数据,得出了明确的结论:在中大型任务场景下,多核并行已经能够稳定地带来明显的正向收益。 具体的几组明确结果如下:
- mid_balanced 场景:1-core 的平均提交时间从 56.158 ms 降到了 3-core 的 39.204 ms,加速比达到了 1.432x,并行效率为 47.75%。
- throughput_heavy 场景:1-core 的平均提交时间从 76.605 ms 降到了 40.824 ms,加速比提升至 1.876x,并行效率达到了 62.55%。
- llama_decode_like 场景:1-core 平均提交时间从 423.358 ms 降到了 231.858 ms,加速比达到 1.826x,并行效率为 60.86%。 结论:数据有力地证明了,在重负载(如吞吐密集型和模拟大模型推理场景)下,当前的 crate 化调度机制和多核分发路径是稳定且具备实战价值的。但在极小任务(如 tiny_dispatch)下,由于调度本身的软件开销,多核加速比不明显甚至可能出现负收益,这也为下阶段(如探索 fast-path 或 batching 提交)指明了优化方向。
RK3588 RKNPU 开发文档
本文档基于 RockChip官方开源仓库和 StarryOS 仓库中对 RK3588 NPU 运行时库(闭源 librknnrt.so)及内核侧 RKNPU DRM 驱动的逆向与复现成果,整理为三个核心章节:
文档结构
| 章节 | 内容 | 适用场景 |
|---|---|---|
| RKNN 硬件特性 | 三核架构、数据精度与算力、支持的推理框架 | 了解硬件能力边界 |
| 寄存器地图 | 按模块梳理rknpu内部各个寄存器的位域、读写属性 | 写驱动、调试硬件交互 |
| IOCTL协议与数据结构 | DRM_IOCTL_RKNPU_* 命令表,结构体布局,flags枚举,mmap 规则 | 实现ioctl分发,对齐用户态ABI |
| 任务提交流程 | 从用户态提交到硬件执行完成的完整时序逻辑,包含状态机和各种失败路径 | 查询job生命周期 |
| 当前提交-IRQ 边界快照恢复系统 | 总结 step-submit、owner 切换、IRQ 边界快照/写坏/恢复/校验,以及相关 struct 的职责 | 整理当前实验实现、查数据结构分工、回顾抢占边界语义 |
来源标注约定
文档中对每条信息标注来源,使用以下标记:
- Linux rknpu 驱动 — 来自Rockchip官方仓库中rk3588-npu内核驱动代码
- rknpu-ioctl.h — 来自 Linux rknpu 驱动include目录的 ioctl 头文件
- StarryOS Rust 驱动 — 来自
drivers/rknpu/src/的 Rust 复刻实现 - 逆向推断 — 基于代码行为推断,无官方文档确认
术语速查
| 术语 | 含义 |
|---|---|
| GEM | Graphics Execution Manager,DRM 子系统的内存对象管理框架 |
| PC | Program Counter / 任务控制器,NPU 的命令流执行引擎 |
| CNA | Convolution Neural-network Accelerator,卷积加速单元 |
| DPU | Data Processing Unit,数据后处理单元 |
| PPU | Pooling Processing Unit,池化处理单元 |
| DDMA/SDMA | Data DMA / System DMA,数据搬运引擎 |
| IOVA | I/O Virtual Address,IOMMU 映射后的设备侧虚拟地址 |
| fence | DMA fence,用于 job 完成通知与跨设备同步的内核原语 |
RKNN 手册
本栏汇总 RK3588 NPU 的硬件参考与软件接口文档。
硬件手册
NPU 三核架构、数据精度、寄存器位域详解。
IOCTL 协议
DRM_IOCTL_RKNPU_* 命令表、结构体布局、mmap 规则。
任务提交流程
从用户态提交到硬件执行完成的完整时序。
RKNN 硬件手册
来源:RK3588 TRM Chapter 36 RKNN
本章汇总 RK3588 NPU 硬件相关文档,包括硬件特性概览与完整寄存器参考。
RKNN 硬件特性
- 三核 NPU,支持三核协同 / 双核协同 / 单核独立
- 每核 384KB 内部缓冲,AHB 配置接口 + AXI 数据接口
- 支持 INT4 / INT8 / INT16 / FP16 / BF16 / TF32 多精度推理
- 功能流水线:CNA(卷积)→ CORE(MAC)→ DPU(后处理)→ PPU(池化)
- 激活函数:ReLU / Leaky ReLU / ReLUx / Sigmoid / Tanh / Softmax
- 池化:Average / Max / Min Pooling
寄存器图
每个核心拥有独立 64KB 寄存器空间,按功能模块划分:
| 模块 | 地址范围 | 功能 |
|---|---|---|
| PC | 0x0000 ~ 0x0FFF | 任务控制器 / 命令流引擎 |
| CNA | 0x1000 ~ 0x1FFF | 卷积神经网络加速单元 |
| CORE | 0x3000 ~ 0x3FFF | MAC 核心控制 |
| DPU | 0x4000 ~ 0x4FFF | 数据后处理单元 |
| DPU_RDMA | 0x5000 ~ 0x5FFF | DPU 读 DMA |
| PPU | 0x6000 ~ 0x6FFF | 池化处理单元 |
| PPU_RDMA | 0x7000 ~ 0x7FFF | PPU 读 DMA |
| DDMA | 0x8000 ~ 0x8FFF | Data DMA 引擎 |
| SDMA | 0x9000 ~ 0x9FFF | System DMA 引擎 |
| GLOBAL | 0xF000 ~ 0xFFFF | 全局使能掩码 |
RKNN 硬件特性概览
来源:RK3588 TRM Chapter 36 RKNN
RKNN 是专用于神经网络的处理单元,旨在加速人工智能(AI)领域的神经网络运算,涵盖机器视觉和自然语言处理等方向。AI 的应用范围正在不断扩大,目前已在多个领域提供功能支持,包括人脸追踪、手势与肢体追踪、图像分类、视频监控、自动语音识别(ASR)以及高级驾驶辅助系统(ADAS)。
核心特性
| 特性 | 说明 |
|---|---|
| 核心数量 | 三核 NPU(Triple NPU CORE) |
| 协作模式 | 支持三核协同、双核协同、单核独立工作 |
| 配置接口 | AHB 接口,仅用于寄存器配置(单次访问) |
| 数据接口 | AXI 接口,用于从内存取数据 |
| 内部缓冲 | 384KB × 3(每核 384KB) |
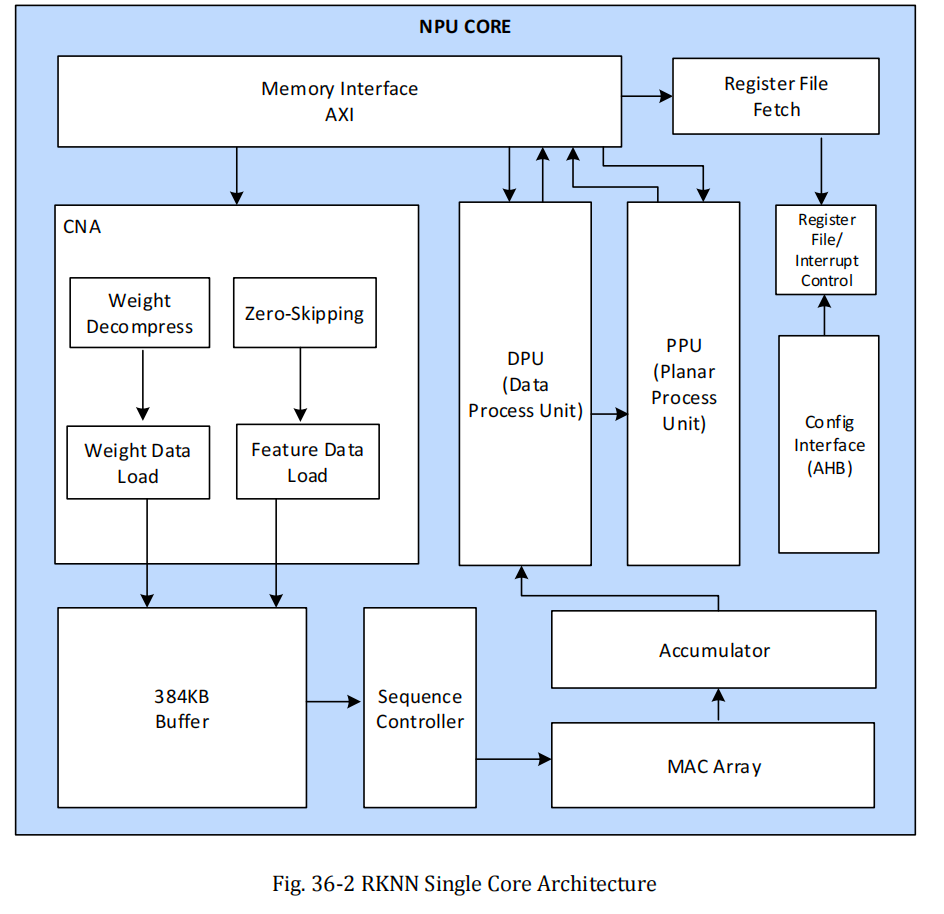
功能模块描述
AHB / AXI 接口
AXI 主接口用于从挂载在 SoC AXI 互联总线上的内存中取数据。AHB 从接口用于访问寄存器,进行配置、调试和测试。
神经网络加速引擎(Neural Network Accelerating Engine)
该引擎是神经网络运算的核心处理单元,包含卷积预处理控制器、内部缓冲区、MAC 阵列和累加器。它为识别功能提供并行卷积 MAC 运算,支持 INT4、INT8、INT16、FP16、BF16 和 TF32 数据类型。
数据处理单元(Data Processing Unit, DPU)
数据处理单元主要负责单数据运算,如 Leaky ReLU、ReLU、ReLUx、Sigmoid、Tanh 等激活函数。同时提供 Softmax、转置(Transpose)、数据格式转换等功能。
平面处理单元(Planar Processing Unit, PPU)
平面处理单元在数据处理单元输出之后执行平面操作,支持平均池化(Average Pooling)、最大池化(Max Pooling)、最小池化(Min Pooling)等。
寄存器配置取数单元(Register File Fetch Unit, PC)
寄存器配置取数单元通过 AXI 接口从外部系统内存中获取寄存器配置(即命令流),实现硬件自动配置各功能模块寄存器。
支持的数据精度与算力
| 数据类型 | 每周期 MAC 操作数(三核合计) |
|---|---|
| INT4 | 2048 × 3 = 6144 |
| INT8 | 1024 × 3 = 3072 |
| INT16 | 512 × 3 = 1536 |
| FP16 | 512 × 3 = 1536 |
| BF16 | 512 × 3 = 1536 |
| TF32 | 256 × 3 = 768 |
支持的推理框架
TensorFlow、Caffe、TFLite、PyTorch、ONNX NN、Android NN 等。
寄存器地图
RK3588 NPU 每个核心(共 3 核)拥有独立的寄存器空间,内部按功能模块划分为以下区域:
地址空间总览
| Base[15:12] | 模块 | 大小 | 地址范围 | 功能 |
|---|---|---|---|---|
4'h0 | PC | 4KB | 0x0000 ~ 0x0FFF | 任务控制器 / 命令流引擎 |
4'h1 | CNA | 4KB | 0x1000 ~ 0x1FFF | 卷积神经网络加速单元 |
4'h3 | CORE | 4KB | 0x3000 ~ 0x3FFF | MAC 核心控制 |
4'h4 | DPU | 4KB | 0x4000 ~ 0x4FFF | 数据后处理单元 |
4'h5 | DPU_RDMA | 4KB | 0x5000 ~ 0x5FFF | DPU 读 DMA |
4'h6 | PPU | 4KB | 0x6000 ~ 0x6FFF | 池化处理单元 |
4'h7 | PPU_RDMA | 4KB | 0x7000 ~ 0x7FFF | PPU 读 DMA |
4'h8 | DDMA | 4KB | 0x8000 ~ 0x8FFF | Data DMA 引擎 |
4'h9 | SDMA | 4KB | 0x9000 ~ 0x9FFF | System DMA 引擎 |
4'hF | GLOBAL | 4B | 0xF000 ~ 0xF004 | 全局使能掩码 |
来源说明:地址映射来自 RK3588 TRM Table 1-1 RKNN Address Mapping。
PC 寄存器块(Program Counter / 任务控制器)
基址:CORE_BASE + 0x0000 | 地址范围:0x0000 ~ 0x0FFF
来源:RK3588 TRM §36.4.3 Detail Registers Description
PC 是 NPU 的命令流执行引擎,负责:从 DMA 地址读取寄存器命令流 → 按序写入各功能模块寄存器 → 触发执行 → 产生完成中断。
RKNN_pc_version(0x0000)
硬件版本寄存器(只读)。驱动通过 version + (version_num & 0xFFFF) 计算完整版本号。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RO | 0x0 | version | 硬件版本标识 |
RKNN_pc_version_num(0x0004)
硬件版本号寄存器(只读)。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:16 | RO | 0x0 | — | 保留 |
| 15:0 | RO | 0x0 | version_num | 硬件版本编号 |
RKNN_pc_operation_enable(0x0008)
操作使能寄存器。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:1 | RO | 0x0 | — | 保留 |
| 0 | RW | 0x0 | op_en | PC 操作使能。0:禁用 PC 模块;1:使能 PC 模块,为每个 task 取寄存器配置 |
RKNN_pc_base_address(0x0010)
PC 基址寄存器,指定 DMA 指令流所在的内存地址。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:4 | RW | 0x0 | pc_source_addr | PC 基址。DMA 指令流所在的内存地址 |
| 3:1 | RO | 0x0 | — | 保留 |
| 0 | RW | 0x0 | pc_sel | PC 模式选择。0:PC 模式,通过 AXI DMA 取寄存器配置;1:Slave 模式,通过 AHB 设置寄存器 |
RKNN_pc_register_amounts(0x0014)
每个 task 需要取的寄存器数量。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:16 | RO | 0x0 | — | 保留 |
| 15:0 | RW | 0x0 | pc_data_amount | 数据量。一个 task 需要取的寄存器数量 |
每条寄存器指令占 64 bit,格式如下:
| 位域 | 含义 |
|---|---|
[63:48] | 目标模块选择(哪个 block) |
[47:16] | 寄存器值 |
[15:0] | 各 block 内的偏移地址 |
模块选择位:
| Bit | 目标模块 |
|---|---|
| 56 | PC |
| 57 | CNA |
| 59 | CORE |
| 60 | DPU |
| 61 | DPU_RDMA |
| 62 | PPU |
| 63 | PPU_RDMA |
| 55 | 设置各 block 的 op_en |
示例:
64'h0081_0000_007f_0008将设置各 block 的 op_en(CNA, CORE, ..., PPU_RDMA)。注意:
op_en强烈建议放在寄存器列表末尾。在op_en之前,必须先设置64'h0041_xxxx_xxxx_xxxx。
RKNN_pc_interrupt_mask(0x0020)
中断掩码寄存器。置 1 使能对应中断。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:17 | RO | 0x0 | — | 保留 |
| 16:0 | RW | 0x1FFFF | int_mask | 中断掩码(见下表) |
| Bit | 中断源 |
|---|---|
| 0 | CNA feature group 0 |
| 1 | CNA feature group 1 |
| 2 | CNA weight group 0 |
| 3 | CNA weight group 1 |
| 4 | CNA csc group 0 |
| 5 | CNA csc group 1 |
| 6 | CORE group 0 |
| 7 | CORE group 1 |
| 8 | DPU group 0 |
| 9 | DPU group 1 |
| 10 | PPU group 0 |
| 11 | PPU group 1 |
| 12 | DMA read error |
| 13 | DMA write error |
注意:在 PC 模式下,int_mask 设置的是最后一个 task 的中断掩码。
RKNN_pc_interrupt_clear(0x0024)
中断清除寄存器。写 1 清除对应中断位。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:17 | RO | 0x0 | — | 保留 |
| 16:0 | W1C | 0x0 | int_clr | 中断清除(位定义同 int_mask) |
INT_CLEAR_ALL = 0x1FFFF(清除 bit0~bit16 全部中断)rknpu-ioctl.h
RKNN_pc_interrupt_status(0x0028)
中断状态寄存器(经过 mask 后的状态)。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:17 | RO | 0x0 | — | 保留 |
| 16:0 | W1C | 0x0 | int_st | 中断状态,与 mask 位做 AND(位定义同 int_mask) |
RKNN_pc_interrupt_raw_status(0x002C)
中断原始状态寄存器(未经 mask 的原始状态)。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:17 | RO | 0x0 | — | 保留 |
| 16:0 | W1C | 0x0 | int_raw_st | 中断原始状态(位定义同 int_mask) |
RKNN_pc_task_con(0x0030)
任务控制寄存器。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:14 | RO | 0x0 | — | 保留 |
| 13 | W1C | 0x0 | task_count_clear | 任务计数器清除。清除当前 task 计数器,建议在 task 启动前清除 |
| 12 | RW | 0x0 | task_pp_en | Ping-pong 模式使能。0:关闭,第二组寄存器在第一组 task 完成后才取;1:开启,第二组寄存器在第一组取完后立即开始取 |
| 11:0 | RW | 0x0 | task_number | 要执行的 task 总数 |
RKNN_pc_task_dma_base_addr(0x0034)
任务 DMA 基址寄存器。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:4 | RW | 0x0 | dma_base_addr | 任务基址。各 DMA(feature DMA、weight DMA、DPU DMA、PPU DMA)的地址设为偏移地址,AXI 总线上的最终地址 = 基址 + 偏移地址 |
| 3:0 | RO | 0x0 | — | 保留 |
RKNN_pc_task_status(0x003C)
任务状态寄存器(只读)。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:28 | RO | 0x0 | — | 保留 |
| 27:0 | RW | 0x0 | task_status | 任务状态(见下表) |
| 位域 | 含义 |
|---|---|
| [11:0] | 当前 task 计数器值 |
| [12] | 指示第一个 task 正在执行 / 第一个 task 的寄存器正在取 |
| [13] | 指示最后一个 task 正在执行 / 最后一个 task 的寄存器正在取 |
附:驱动层补充
中断状态归一化(rknpu_fuzz_status())
StarryOS Rust 驱动 在判定完成前,对 interrupt_status 做如下归一化处理:
| 位组 | 掩码 | 归一化规则 | 对应模块 |
|---|---|---|---|
| bit[1:0] | 0x03 | 任一非零 → 置 0x03 | CNA_FG |
| bit[3:2] | 0x0C | 任一非零 → 置 0x0C | CNA_WG |
| bit[5:4] | 0x30 | 任一非零 → 置 0x30 | CNA_CSC |
| bit[7:6] | 0xC0 | 任一非零 → 置 0xC0 | CORE |
| bit[9:8] | 0x300 | 任一非零 → 置 0x300 | DPU |
| bit[11:10] | 0xC00 | 任一非零 → 置 0xC00 | PPU |
含义 逆向推断:每个功能模块有 2 个中断 bit(G0/G1),硬件可能只置其中一个,但驱动判定完成时需要两个都为 1,因此做归一化。
CNA 寄存器块(Convolution Neural-network Accelerator)
基址:CORE_BASE + 0x1000 | 地址范围:0x1000 ~ 0x1FFF
来源:RK3588 TRM §36.4.3 Detail Registers Description
CNA 是卷积加速单元,包含特征数据加载、权重加载、384KB 内部缓冲(CBUF)、序列扫描控制器(CSC)。
RKNN_cna_s_status(0x1000)
执行器状态寄存器(只读)。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:18 | RO | 0x0 | — | 保留 |
| 17:16 | RO | 0x0 | status_1 | 执行器 1 状态。0:空闲;1:正在执行;2:正在执行且执行器 1 等待执行;3:保留 |
| 15:2 | RO | 0x0 | — | 保留 |
| 1:0 | RO | 0x0 | status_0 | 执行器 0 状态。0:空闲;1:正在执行;2:正在执行且执行器 1 等待执行;3:保留 |
RKNN_cna_s_pointer(0x1004)
寄存器组指针与 ping-pong 控制。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:17 | RO | 0x0 | — | 保留 |
| 16 | RO | 0x0 | executer | 当前使用的寄存器组。0:执行器组 0;1:执行器组 1 |
| 15:6 | RO | 0x0 | — | 保留 |
| 5 | W1C | 0x0 | executer_pp_clear | 清除执行器组指针,写 1 清零 |
| 4 | W1C | 0x0 | pointer_pp_clear | 清除寄存器组指针,写 1 清零 |
| 3 | RW | 0x0 | pointer_pp_mode | Ping-pong 模式。0:按执行器切换(executer 0 完成后切到 1);1:按指针切换(pointer 0 完成后切到 1) |
| 2 | RW | 0x0 | executer_pp_en | 执行器组 ping-pong 使能。0:禁用;1:使能 |
| 1 | RW | 0x0 | pointer_pp_en | 寄存器组 ping-pong 使能。0:禁用;1:使能 |
| 0 | RW | 0x0 | pointer | 当前待设置的寄存器组。0:组 0;1:组 1 |
RKNN_cna_operation_enable(0x1008)
操作使能寄存器。写入此寄存器将触发 CNA 模块开始执行。此寄存器及之后的寄存器均为 ping-pong 影子寄存器。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:1 | RO | 0x0 | — | 保留 |
| 0 | RW | 0x0 | op_en | CNA 操作使能。0:禁用;1:使能 |
RKNN_cna_conv_con1(0x100C)
卷积控制寄存器 1:精度、模式、反卷积等。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31 | RO | 0x0 | — | 保留 |
| 30 | RW | 0x0 | nonalign_dma | CNA DMA 非对齐模式。0:禁用;1:使能(ARGB 模式下请开启,使 DMA 连续取特征数据) |
| 29 | RW | 0x0 | group_line_off | 组行取数关闭。0:使能组行取数;1:禁用(仅影响取数效率) |
| 28:17 | RO | 0x0 | — | 保留 |
| 16 | RW | 0x0 | deconv | 反卷积使能。0:禁用;1:使能 |
| 15:12 | RW | 0x0 | argb_in | 非对齐通道层控制。8:1 通道输入;9:2 通道;10:3 通道;11:4 通道 |
| 11:10 | RO | 0x0 | — | 保留 |
| 9:7 | RW | 0x0 | proc_precision | 处理精度。0:int8;1:int16;2:fp16;3:bf16;6:int4;7:tf32 |
| 6:4 | RW | 0x0 | in_precision | 输入精度。编码同 proc_precision |
| 3:0 | RW | 0x0 | conv_mode | 卷积模式。0:直接卷积;3:深度可分离卷积(Depthwise) |
RKNN_cna_conv_con2(0x1010)
卷积控制寄存器 2:kernel 分组、feature grain、CSC 控制。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:24 | RO | 0x0 | — | 保留 |
| 23:16 | RW | 0x0 | kernel_group | Kernel 分组数。int8 下 32 个 kernel 为 1 组,int16/fp16 下 16 个为 1 组。例:256 个 kernel,int8 下设为 256/32−1=7 |
| 15:14 | RO | 0x0 | — | 保留 |
| 13:4 | RW | 0x0 | feature_grains | 卷积开始前需缓冲的特征数据行数。建议设为 y_stride + weight_height + 1 |
| 3 | RO | 0x0 | — | 保留 |
| 2 | RW | 0x0 | csc_wo_en | 权重扫描控制。0:使能 CSC 输出权重到 CORE;1:禁用 |
| 1 | RW | 0x0 | csc_do_en | 数据扫描控制。0:使能 CSC 输出特征数据到 CORE;1:禁用 |
| 0 | RW | 0x0 | cmd_fifo_srst | 命令 FIFO 软复位(调试用) |
RKNN_cna_conv_con3(0x1014)
卷积控制寄存器 3:多核模式、空洞卷积、反卷积步长、卷积步长。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31 | RO | 0x0 | — | 保留 |
| 30:28 | RW | 0x0 | nn_mode | 多核协作模式。0:32×32(单核);1:64×32;2:96×32;4:32×64;5:32×96。单核模式保持 0 |
| 27:26 | RO | 0x0 | — | 保留 |
| 25:21 | RW | 0x0 | atrous_y_dilation | 空洞卷积 Y 方向膨胀值(列方向两像素间插入的 pad 数) |
| 20:16 | RW | 0x0 | atrous_x_dilation | 空洞卷积 X 方向膨胀值(行方向两像素间插入的 pad 数)。>0 时启用空洞卷积 |
| 15:14 | RO | 0x0 | — | 保留 |
| 13:11 | RW | 0x0 | deconv_y_stride | 反卷积 Y 步长 |
| 10:8 | RW | 0x0 | deconv_x_stride | 反卷积 X 步长 |
| 7:6 | RO | 0x0 | — | 保留 |
| 5:3 | RW | 0x0 | conv_y_stride | 卷积 Y 步长 |
| 2:0 | RW | 0x0 | conv_x_stride | 卷积 X 步长 |
RKNN_cna_data_size0(0x1020)
输入特征数据宽高。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:27 | RO | 0x0 | — | 保留 |
| 26:16 | RW | 0x0 | datain_width | 输入特征数据宽度 |
| 15:11 | RO | 0x0 | — | 保留 |
| 10:0 | RW | 0x0 | datain_height | 输入特征数据高度 |
RKNN_cna_data_size1(0x1024)
输入特征数据通道数。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:30 | RO | 0x0 | — | 保留 |
| 29:16 | RW | 0x0 | datain_channel_real | 真实通道数。当输入通道不是 8(int8)或 4(int16/fp16)的整数倍时,设置此字段 |
| 15:0 | RW | 0x0 | datain_channel | 输入通道数。int8 须为 8 的整数倍;int16/fp16 须为 4 的整数倍 |
RKNN_cna_data_size2(0x1028)
卷积后输出数据宽度。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:11 | RO | 0x0 | — | 保留 |
| 10:0 | RW | 0x0 | dataout_width | 卷积后数据宽度 |
RKNN_cna_data_size3(0x102C)
卷积后输出数据 surface 模式与总像素数。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:24 | RO | 0x0 | — | 保留 |
| 23:22 | RW | 0x0 | surf_mode | Surface 串行模式。0/1:1 surf;2:2 surf;3:4 surf |
| 21:0 | RW | 0x0 | dataout_atomics | 卷积后输出总像素数 |
RKNN_cna_weight_size0(0x1030)
权重总字节数。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | weight_bytes | 本次卷积的权重总字节数 |
RKNN_cna_weight_size1(0x1034)
单个 kernel 的权重字节数。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:19 | RO | 0x0 | — | 保留 |
| 18:0 | RW | 0x0 | weight_bytes_per_kernel | 单个 kernel 的权重字节数 |
RKNN_cna_weight_size2(0x1038)
Kernel 宽高与数量。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:29 | RO | 0x0 | — | 保留 |
| 28:24 | RW | 0x0 | weight_width | Kernel 宽度 |
| 23:21 | RO | 0x0 | — | 保留 |
| 20:16 | RW | 0x0 | weight_height | Kernel 高度 |
| 15:14 | RO | 0x0 | — | 保留 |
| 13:0 | RW | 0x0 | weight_kernels | Kernel 数量 |
RKNN_cna_cbuf_con0(0x1040)
CBUF(内部缓冲)控制寄存器 0:数据/权重复用、Bank 分配。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:14 | RO | 0x0 | — | 保留 |
| 13 | RW | 0x0 | weight_reuse | 权重数据复用使能。0:禁用;1:使能,直接从内部缓冲取权重 |
| 12 | RW | 0x0 | data_reuse | 特征数据复用使能。0:禁用;1:使能,直接从内部缓冲取数据 |
| 11 | RO | 0x0 | — | 保留 |
| 10:8 | RW | 0x0 | fc_data_bank | FC 零跳过模式的特征数据 Bank 数。FC 零跳过模式设为 1,否则必须为 0 |
| 7:4 | RW | 0x0 | weight_bank | 权重数据占用的 Bank 数。1:Bank 7;2:Bank 6-7;…;7:Bank 1-7 |
| 3:0 | RW | 0x0 | data_bank | 特征数据占用的 Bank 数。0:Bank 0;1:Bank 0-1;…;6:Bank 0-6 |
RKNN_cna_cbuf_con1(0x1044)
CBUF 控制寄存器 1。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:13 | RO | 0x0 | — | 保留 |
| 12:0 | RW | 0x0 | data_entries | 存储一行特征图所需的 Bank 空间 |
RKNN_cna_cvt_con0(0x104C)
输入转换控制寄存器 0:CVT 截断值、符号、舍入、旁路。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:28 | RO | 0x0 | — | 保留 |
| 27:22 | RW | 0x0 | cvt_truncate_3 | CVT 截断值 3 |
| 21:16 | RW | 0x0 | cvt_truncate_2 | CVT 截断值 2 |
| 15:10 | RW | 0x0 | cvt_truncate_1 | CVT 截断值 1 |
| 9:4 | RW | 0x0 | cvt_truncate_0 | CVT 截断值 0 |
| 3 | RW | 0x0 | data_sign | 特征数据符号。0:无符号;1:有符号 |
| 2 | RW | 0x0 | round_type | 舍入类型。0:奇入偶不入;1:0.5 向上进 1 |
| 1 | RW | 0x0 | cvt_type | 转换运算顺序。0:先乘后加;1:先加后乘 |
| 0 | RW | 0x0 | cvt_bypass | 旁路输入转换。0:使能 CVT;1:禁用 CVT |
RKNN_cna_cvt_con1(0x1050)
输入转换控制 1:第 1 通道的 scale 和 offset。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:16 | RW | 0x0 | cvt_scale0 | CVT 缩放 0(第 1 通道乘法操作数) |
| 15:0 | RW | 0x0 | cvt_offset0 | CVT 偏移 0(第 1 通道加法操作数) |
RKNN_cna_cvt_con2(0x1054)
输入转换控制 2:第 2 通道。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:16 | RW | 0x0 | cvt_scale1 | CVT 缩放 1(第 2 通道乘法操作数) |
| 15:0 | RW | 0x0 | cvt_offset1 | CVT 偏移 1(第 2 通道加法操作数) |
RKNN_cna_cvt_con3(0x1058)
输入转换控制 3:第 3 通道。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:16 | RW | 0x0 | cvt_scale2 | CVT 缩放 2(第 3 通道乘法操作数) |
| 15:0 | RW | 0x0 | cvt_offset2 | CVT 偏移 2(第 3 通道加法操作数) |
RKNN_cna_cvt_con4(0x105C)
输入转换控制 4:第 4 通道。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:16 | RW | 0x0 | cvt_scale3 | CVT 缩放 3(第 4 通道乘法操作数) |
| 15:0 | RW | 0x0 | cvt_offset3 | CVT 偏移 3(第 4 通道加法操作数) |
RKNN_cna_fc_con0(0x1060)
全连接零跳过控制 0。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:16 | RW | 0x0 | fc_skip_data | FC 零跳过数据值(通常设为 0) |
| 15:1 | RO | 0x0 | — | 保留 |
| 0 | RW | 0x0 | fc_skip_en | FC 零跳过使能。0:禁用;1:使能。当某像素特征数据为 0 时,跳过对应权重的取数 |
RKNN_cna_fc_con1(0x1064)
全连接零跳过控制 1。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:17 | RO | 0x0 | — | 保留 |
| 16:0 | RW | 0x0 | data_offset | FC 零跳过模式下的特征数据偏移 |
RKNN_cna_pad_con0(0x1068)
Pad 控制寄存器 0。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:8 | RO | 0x0 | — | 保留 |
| 7:4 | RW | 0x0 | pad_left | 特征图左侧 pad 数 |
| 3:0 | RW | 0x0 | pad_top | 特征图顶部 pad 数 |
RKNN_cna_feature_data_addr(0x1070)
输入特征数据基址。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | feature_base_addr | 特征数据地址 |
RKNN_cna_fc_con2(0x1074)
权重数据地址偏移。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:17 | RO | 0x0 | — | 保留 |
| 16:0 | RW | 0x0 | weight_offset | 权重数据地址偏移 |
RKNN_cna_dma_con0(0x1078)
AXI DMA 控制寄存器 0:burst 长度。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31 | RW | 0x0 | ov4k_bypass | 超 4K burst 拆分。0:使能(将超 4K 的 burst 拆为 2 个);1:旁路 |
| 30:20 | RO | 0x0 | — | 保留 |
| 19:16 | RW | 0x0 | weight_burst_len | 权重 DMA AXI burst 长度。3:burst=4;7:burst=8;15:burst=16 |
| 15:4 | RO | 0x0 | — | 保留 |
| 3:0 | RW | 0x0 | data_burst_len | 特征 DMA AXI burst 长度。编码同上 |
RKNN_cna_dma_con1(0x107C)
行步长(Line stride)。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:28 | RO | 0x0 | — | 保留 |
| 27:0 | RW | 0x0 | line_stride | 行步长。含虚拟框(Virtual box)的特征宽度 |
RKNN_cna_dma_con2(0x1080)
Surface 步长。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:28 | RO | 0x0 | — | 保留 |
| 27:0 | RW | 0x0 | surf_stride | Surface 步长。特征图实际 surface 面积 |
RKNN_cna_fc_data_size0(0x1084)
FC 模式下 AXI DMA 的特征输入宽高。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:30 | RO | 0x0 | — | 保留 |
| 29:16 | RW | 0x0 | dma_width | AXI DMA 特征输入宽度 |
| 15:11 | RO | 0x0 | — | 保留 |
| 10:0 | RW | 0x0 | dma_height | AXI DMA 特征输入高度 |
RKNN_cna_fc_data_size1(0x1088)
FC 模式下 AXI DMA 的特征输入通道数。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:16 | RO | 0x0 | — | 保留 |
| 15:0 | RW | 0x0 | dma_channel | AXI DMA 特征输入通道数 |
RKNN_cna_clk_gate(0x1090)
时钟门控控制寄存器。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:5 | RO | 0x0 | — | 保留 |
| 4 | RW | 0x0 | cbuf_cs_disable_clkgate | CBUF 自动时钟门控。0:使能自动门控;1:禁用 CBUF 时钟门控 |
| 3 | RO | 0x0 | — | 保留 |
| 2 | RW | 0x0 | csc_disable_clkgate | CSC 自动时钟门控。0:使能;1:禁用 CSC 时钟门控 |
| 1 | RW | 0x0 | cna_weight_disable_clkgate | 权重取数自动时钟门控。0:使能;1:禁用 |
| 0 | RW | 0x0 | cna_feature_disable_clkgate | 特征取数自动时钟门控。0:使能;1:禁用 |
RKNN_cna_dcomp_ctrl(0x1100)
权重解压控制寄存器。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:4 | RO | 0x0 | — | 保留 |
| 3 | RW | 0x0 | wt_dec_bypass | 旁路权重解压 |
| 2:0 | RW | 0x0 | decomp_control | 权重解压控制 |
RKNN_cna_dcomp_regnum(0x1104)
权重解压寄存器数。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | dcomp_regnum | 权重解压寄存器数量 |
RKNN_cna_dcomp_addr0(0x1110)
权重基址。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:4 | RW | 0x0 | decompress_addr0 | 权重基址 |
| 3:0 | RO | 0x0 | — | 保留 |
RKNN_cna_dcomp_amount0~15(0x1140 ~ 0x117C)
权重解压量寄存器,共 16 个,偏移 0x1140 + N×4(N = 0~15)。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | dcomp_amountN | 第 N 次解压的权重数据量 |
RKNN_cna_cvt_con5(0x1180)
按通道 CVT 使能。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | per_channel_cvt_en | 按通道使能 CVT 功能。int4 共 32 通道(128 bit),int8 共 16 通道 |
RKNN_cna_pad_con1(0x1184)
Pad 值寄存器。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | pad_value | Pad 填充值 |
CORE 寄存器块(MAC 核心控制)
基址:CORE_BASE + 0x3000 | 地址范围:0x3000 ~ 0x3FFF
来源:RK3588 TRM §36.4.3 Detail Registers Description
CORE 模块包含 MAC 阵列和累加器,负责卷积乘累加运算。
RKNN_core_s_status(0x3000)
执行器状态寄存器(只读)。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:18 | RO | 0x0 | — | 保留 |
| 17:16 | RO | 0x0 | status_1 | 执行器 1 状态。0:空闲;1:正在执行;2:正在执行且执行器 1 等待执行;3:保留 |
| 15:2 | RO | 0x0 | — | 保留 |
| 1:0 | RO | 0x0 | status_0 | 执行器 0 状态。编码同 status_1 |
RKNN_core_s_pointer(0x3004)
寄存器组指针与 ping-pong 控制。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:17 | RO | 0x0 | — | 保留 |
| 16 | RO | 0x0 | executer | 当前使用的寄存器组。0:执行器组 0;1:执行器组 1 |
| 15:6 | RO | 0x0 | — | 保留 |
| 5 | W1C | 0x0 | executer_pp_clear | 清除执行器组指针,写 1 清零 |
| 4 | W1C | 0x0 | pointer_pp_clear | 清除寄存器组指针,写 1 清零 |
| 3 | RW | 0x0 | pointer_pp_mode | Ping-pong 模式。0:按执行器切换;1:按指针切换 |
| 2 | RW | 0x0 | executer_pp_en | 执行器组 ping-pong 使能。0:禁用;1:使能 |
| 1 | RW | 0x0 | pointer_pp_en | 寄存器组 ping-pong 使能。0:禁用;1:使能 |
| 0 | RW | 0x0 | pointer | 当前待设置的寄存器组。0:组 0;1:组 1 |
RKNN_core_operation_enable(0x3008)
操作使能寄存器。写入此寄存器将触发 CORE 模块开始执行。此寄存器及之后的寄存器均为 ping-pong 影子寄存器。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:1 | RO | 0x0 | — | 保留 |
| 0 | RW | 0x0 | op_en | CORE 操作使能。0:禁用;1:使能 |
RKNN_core_mac_gating(0x300C)
MAC 软时钟门控寄存器。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:27 | RO | 0x0 | — | 保留 |
| 26:0 | RW | 0x7800800 | slcg_op_en | 软时钟门控信号 |
注意:复位值为
0x07800800,与其他寄存器不同。
RKNN_core_misc_cfg(0x3010)
杂项配置寄存器:精度、深度可分离、量化使能。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:20 | RO | 0x0 | — | 保留 |
| 19:14 | RW | 0x0 | soft_gating | 累加器软门控信号 |
| 13:11 | RO | 0x0 | — | 保留 |
| 10:8 | RW | 0x0 | proc_precision | 处理精度。0:int8;1:int16;2:fp16;3:bf16;6:int4;7:tf32 |
| 7:2 | RO | 0x0 | — | 保留 |
| 1 | RW | 0x0 | dw_en | 深度可分离模式使能。0:禁用;1:使能 Depthwise 模式 |
| 0 | RW | 0x0 | qd_en | 量化特征数据计算使能。0:禁用;1:使能 |
RKNN_core_dataout_size_0(0x3014)
输出特征尺寸寄存器 0:宽高。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:16 | RW | 0x0 | dataout_height | 激活后输出数据高度 |
| 15:0 | RW | 0x0 | dataout_width | 激活后输出数据宽度 |
RKNN_core_dataout_size_1(0x3018)
输出特征尺寸寄存器 1:通道数。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:16 | RO | 0x0 | — | 保留 |
| 15:0 | RW | 0x0 | dataout_channel | 激活后输出数据通道数 |
RKNN_core_clip_truncate(0x301C)
截断与舍入控制寄存器。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:7 | RO | 0x0 | — | 保留 |
| 6 | RW | 0x0 | round_type | 舍入类型。0:奇入偶不入;1:0.5 向上进 1 |
| 5 | RO | 0x0 | — | 保留 |
| 4:0 | RW | 0x0 | clip_truncate | 截断位数 |
DPU 寄存器块(Data Processing Unit)
基址:CORE_BASE + 0x4000 | 地址范围:0x4000 ~ 0x4FFF
来源:RK3588 TRM §36.4.3 Detail Registers Description
DPU 负责后处理运算,包含三级流水线核心:BS CORE(Bias/Scale)→ BN CORE(Batch Norm)→ EW CORE(Element-Wise),以及输出转换器、LUT 引擎、转置/重组等功能。
RKNN_dpu_s_status(0x4000)
执行器状态寄存器(只读)。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:18 | RO | 0x0 | — | 保留 |
| 17:16 | RO | 0x0 | status_1 | 执行器 1 状态。0:空闲;1:正在执行;2:正在执行且等待执行;3:保留 |
| 15:2 | RO | 0x0 | — | 保留 |
| 1:0 | RO | 0x0 | status_0 | 执行器 0 状态。编码同 status_1 |
RKNN_dpu_s_pointer(0x4004)
寄存器组指针与 ping-pong 控制。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:17 | RO | 0x0 | — | 保留 |
| 16 | RO | 0x0 | executer | 当前使用的寄存器组。0:组 0;1:组 1 |
| 15:6 | RO | 0x0 | — | 保留 |
| 5 | W1C | 0x0 | executer_pp_clear | 清除执行器组指针,写 1 清零 |
| 4 | W1C | 0x0 | pointer_pp_clear | 清除寄存器组指针,写 1 清零 |
| 3 | RW | 0x0 | pointer_pp_mode | Ping-pong 模式。0:按执行器切换;1:按指针切换 |
| 2 | RW | 0x0 | executer_pp_en | 执行器组 ping-pong 使能 |
| 1 | RW | 0x0 | pointer_pp_en | 寄存器组 ping-pong 使能 |
| 0 | RW | 0x0 | pointer | 当前待设置的寄存器组。0:组 0;1:组 1 |
RKNN_dpu_operation_enable(0x4008)
操作使能。写入触发 DPU 执行,此寄存器及之后均为 ping-pong 影子寄存器。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:1 | RO | 0x0 | — | 保留 |
| 0 | RW | 0x0 | op_en | DPU 操作使能。0:禁用;1:使能 |
RKNN_dpu_feature_mode_cfg(0x400C)
特征模式配置:flying mode、输出目标、卷积模式、burst、非对齐、转置、重组。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31 | RW | 0x0 | comb_use | 组合使用,同 DPU_RDMA comb_use[0] |
| 30 | RW | 0x0 | tp_en | 转置使能 |
| 29:26 | RW | 0x0 | rgp_type | 重组类型。0:全部 128bit;1:4bit;2:8bit;3:16bit;4:32bit;5:64bit |
| 25 | RW | 0x0 | nonalign | 非对齐模式使能(输出数据流与输入相同时可用) |
| 24:9 | RW | 0x0 | surf_len | 非对齐模式下存储的 8 字节数 |
| 8:5 | RW | 0x0 | burst_len | Burst 长度。3:Burst4;7:Burst8;15:Burst16 |
| 4:3 | RW | 0x0 | conv_mode | 卷积模式。0:普通卷积;3:Depthwise |
| 2:1 | RW | 0x0 | output_mode | 输出目标。[0]:输出到 PPU;[1]:输出到外部 |
| 0 | RW | 0x0 | flying_mode | Flying 模式。0:主数据来自卷积输出;1:主数据来自 MRDMA |
RKNN_dpu_data_format(0x4010)
数据格式配置:输入/输出/处理精度、负数移位值。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:29 | RW | 0x0 | out_precision | 输出精度。0:int8;1:int16;2:fp16;3:bf16;4:int32;5:fp32;6:int4 |
| 28:26 | RW | 0x0 | in_precision | 输入精度(同 DPU_RDMA)。编码同上 |
| 25:16 | RW | 0x0 | ew_truncate_neg | EW CORE 负数移位值 |
| 15:10 | RW | 0x0 | bn_mul_shift_value_neg | BN CORE 负数移位值 |
| 9:4 | RW | 0x0 | bs_mul_shift_value_neg | BS CORE 负数移位值 |
| 3 | RW | 0x0 | mc_surf_out | 多 surface 输出。0:每像素 16 字节对齐;1:可输出 2/4 surface 串行 |
| 2:0 | RW | 0x0 | proc_precision | 处理精度。编码同 out_precision |
RKNN_dpu_offset_pend(0x4014)
额外通道填充值。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:16 | RO | 0x0 | — | 保留 |
| 15:0 | RW | 0x0 | offset_pend | 额外通道设置值 |
RKNN_dpu_dst_base_addr(0x4020)
目标基址。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:4 | RW | 0x0 | dst_base_addr | 目标基址 |
| 3:0 | RO | 0x0 | — | 保留 |
RKNN_dpu_dst_surf_stride(0x4024)
输出 surface 步长。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:4 | RW | 0x0 | dst_surf_stride | 输出 shape 的 surface 步长 |
| 3:0 | RO | 0x0 | — | 保留 |
RKNN_dpu_data_cube_width(0x4030)
输入 cube 宽度。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:13 | RO | 0x0 | — | 保留 |
| 12:0 | RW | 0x0 | width | 输入 cube 宽度 |
RKNN_dpu_data_cube_height(0x4034)
输入 cube 高度 + minmax 控制。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:25 | RO | 0x0 | — | 保留 |
| 24:22 | RW | 0x0 | minmax_ctl | MinMax 配置。[0]:使能;[1]:类型;[2]:仅概率 |
| 21:13 | RO | 0x0 | — | 保留 |
| 12:0 | RW | 0x0 | height | 输入 cube 高度 |
RKNN_dpu_data_cube_notch_addr(0x4038)
Notch 地址(宽度末尾到 shape 行末的像素数)。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:29 | RO | 0x0 | — | 保留 |
| 28:16 | RW | 0x0 | notch_addr_1 | Notch 地址 1 |
| 15:13 | RO | 0x0 | — | 保留 |
| 12:0 | RW | 0x0 | notch_addr_0 | Notch 地址 0 |
RKNN_dpu_data_cube_channel(0x403C)
输入 cube 通道数。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:29 | RO | 0x0 | — | 保留 |
| 28:16 | RW | 0x0 | orig_channel | 原始输出通道数 |
| 15:13 | RO | 0x0 | — | 保留 |
| 12:0 | RW | 0x0 | channel | Cube 通道数 |
RKNN_dpu_bs_cfg(0x4040)
BS CORE 配置:ALU 算法、操作数来源、ReLU/PRELU/RELUX 控制。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:20 | RO | 0x0 | — | 保留 |
| 19:16 | RW | 0x0 | bs_alu_algo | BS ALU 运算类型。2:Add;4:Minus |
| 15:9 | RO | 0x0 | — | 保留 |
| 8 | RW | 0x0 | bs_alu_src | ALU 操作数来源。0:寄存器;1:外部 |
| 7 | RW | 0x0 | bs_relux_en | RELUX 使能 |
| 6 | RW | 0x0 | bs_relu_bypass | 旁路 BS RELU。0:不旁路;1:旁路 |
| 5 | RW | 0x0 | bs_mul_prelu | MUL PRELU 使能 |
| 4 | RW | 0x0 | bs_mul_bypass | 旁路 BS MUL |
| 3:2 | RO | 0x0 | — | 保留 |
| 1 | RW | 0x0 | bs_alu_bypass | 旁路 BS ALU |
| 0 | RW | 0x0 | bs_bypass | 旁路整个 BS CORE |
RKNN_dpu_bs_alu_cfg(0x4044)
BS ALU 操作数。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | bs_alu_operand | BS CORE ALU 操作数 |
RKNN_dpu_bs_mul_cfg(0x4048)
BS MUL 配置:操作数、移位值、来源。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:16 | RW | 0x0 | bs_mul_operand | BS MUL 操作数 |
| 15:14 | RO | 0x0 | — | 保留 |
| 13:8 | RW | 0x0 | bs_mul_shift_value | BS 正数移位值 |
| 7:2 | RO | 0x0 | — | 保留 |
| 1 | RW | 0x0 | bs_truncate_src | 移位值来源。0:寄存器;1:外部 |
| 0 | RW | 0x0 | bs_mul_src | MUL 操作数来源。0:寄存器;1:外部 |
RKNN_dpu_bs_relux_cmp_value(0x404C)
BS RELUX 比较值。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | bs_relux_cmp_dat | RELUX 比较值 |
RKNN_dpu_bs_ow_cfg(0x4050)
BS OW(CPEND)配置 + 重组计数器 + 转置。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:28 | RW | 0x0 | rgp_cnter | 重组计数器。0:全选;1:每 2 选 1;2:每 4 选 1;3:每 8 选 1 |
| 27 | RW | 0x0 | tp_org_en | 原始转置使能 |
| 26:11 | RO | 0x0 | — | 保留 |
| 10:8 | RW | 0x0 | size_e_2 | 最后一行输出每行 8 通道数(−1) |
| 7:5 | RW | 0x0 | size_e_1 | 中间行输出每行 8 通道数(−1) |
| 4:2 | RW | 0x0 | size_e_0 | 第一行输出每行 8 通道数(−1) |
| 1 | RW | 0x0 | od_bypass | 旁路 CPEND |
| 0 | RW | 0x0 | ow_src | CPEND 操作数来源。0:寄存器;1:外部 |
RKNN_dpu_bs_ow_op(0x4054)
CPEND 操作数。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:16 | RO | 0x0 | — | 保留 |
| 15:0 | RW | 0x0 | ow_op | CPEND 操作数 |
RKNN_dpu_wdma_size_0(0x4058)
DPU WDMA 尺寸 0:转置精度、通道。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:28 | RO | 0x0 | — | 保留 |
| 27 | RW | 0x0 | tp_precision | 转置精度。0:8bit;1:16bit |
| 26:16 | RW | 0x0 | size_c_wdma | WDMA 的 size_c |
| 15:13 | RO | 0x0 | — | 保留 |
| 12:0 | RW | 0x0 | channel_wdma | WDMA 通道数 |
RKNN_dpu_wdma_size_1(0x405C)
DPU WDMA 尺寸 1:宽高。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:29 | RO | 0x0 | — | 保留 |
| 28:16 | RW | 0x0 | height_wdma | WDMA 高度 |
| 15:13 | RO | 0x0 | — | 保留 |
| 12:0 | RW | 0x0 | width_wdma | WDMA 宽度 |
RKNN_dpu_bn_cfg(0x4060)
BN CORE 配置:ALU 算法、操作数来源、ReLU/PRELU/RELUX 控制。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:20 | RO | 0x0 | — | 保留 |
| 19:16 | RW | 0x0 | bn_alu_algo | BN ALU 运算类型。2:Add;4:Minus |
| 15:9 | RO | 0x0 | — | 保留 |
| 8 | RW | 0x0 | bn_alu_src | ALU 操作数来源。0:寄存器;1:外部 |
| 7 | RW | 0x0 | bn_relux_en | RELUX 使能 |
| 6 | RW | 0x0 | bn_relu_bypass | 旁路 BN RELU |
| 5 | RW | 0x0 | bn_mul_prelu | MUL PRELU 使能 |
| 4 | RW | 0x0 | bn_mul_bypass | 旁路 BN MUL |
| 3:2 | RO | 0x0 | — | 保留 |
| 1 | RW | 0x0 | bn_alu_bypass | 旁路 BN ALU |
| 0 | RW | 0x0 | bn_bypass | 旁路整个 BN CORE |
RKNN_dpu_bn_alu_cfg(0x4064)
BN ALU 操作数。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | bn_alu_operand | BN CORE ALU 操作数 |
RKNN_dpu_bn_mul_cfg(0x4068)
BN MUL 配置。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:16 | RW | 0x0 | bn_mul_operand | BN MUL 操作数 |
| 15:14 | RO | 0x0 | — | 保留 |
| 13:8 | RW | 0x0 | bn_mul_shift_value | BN 正数移位值 |
| 7:2 | RO | 0x0 | — | 保留 |
| 1 | RW | 0x0 | bn_truncate_src | 移位值来源。0:寄存器;1:外部 |
| 0 | RW | 0x0 | bn_mul_src | MUL 操作数来源。0:寄存器;1:外部 |
RKNN_dpu_bn_relux_cmp_value(0x406C)
BN RELUX 比较值。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | bn_relux_cmp_dat | BN RELUX 比较数据 |
RKNN_dpu_ew_cfg(0x4070)
EW CORE 配置:ALU 算法(Max/Min/Add/Div/Minus/Abs/Neg/Floor/Ceil)、LUT、转换器、PRELU 等。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31 | RW | 0x0 | ew_cvt_type | EW 输入转换类型。0:先乘后加;1:先加后乘 |
| 30 | RW | 0x0 | ew_cvt_round | EW 输入转换舍入。0:奇入偶不入;1:0.5 向上进 1 |
| 29:28 | RW | 0x0 | ew_data_mode | ERDMA 数据模式 |
| 27:24 | RO | 0x0 | — | 保留 |
| 23:22 | RW | 0x0 | edata_size | ERDMA cube 数据大小。0:4bit;1:8bit;2:16bit;3:32bit |
| 21 | RW | 0x0 | ew_equal_en | MinMax 相等使能 |
| 20 | RW | 0x0 | ew_binary_en | MinMax 二值使能 |
| 19:16 | RW | 0x0 | ew_alu_algo | EW ALU 运算。0:Max;1:Min;2:Add;3:Div;4:Minus;5:Abs;6:Neg;7:Floor;8:Ceil |
| 15:11 | RO | 0x0 | — | 保留 |
| 10 | RW | 0x0 | ew_relux_en | RELUX 使能 |
| 9 | RW | 0x0 | ew_relu_bypass | 旁路 EW RELU |
| 8 | RW | 0x0 | ew_op_cvt_bypass | 旁路 EW 输入转换器 |
| 7 | RW | 0x0 | ew_lut_bypass | 旁路 LUT |
| 6 | RW | 0x0 | ew_op_src | 操作数来源。0:寄存器;1:外部 |
| 5 | RW | 0x0 | ew_mul_prelu | MUL PRELU 使能 |
| 4:3 | RO | 0x0 | — | 保留 |
| 2 | RW | 0x0 | ew_op_type | 运算类型。0:ALU;1:MUL |
| 1 | RW | 0x0 | ew_op_bypass | 旁路 EW ALU 和 MUL |
| 0 | RW | 0x0 | ew_bypass | 旁路整个 EW CORE |
RKNN_dpu_ew_cvt_offset_value(0x4074)
EW 输入转换偏移。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | ew_op_cvt_offset | EW 转换偏移 |
RKNN_dpu_ew_cvt_scale_value(0x4078)
EW 转换缩放与移位。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:22 | RW | 0x0 | ew_truncate | EW CORE 移位值 |
| 21:16 | RW | 0x0 | ew_op_cvt_shift | EW 转换移位值 |
| 15:0 | RW | 0x0 | ew_op_cvt_scale | EW 转换缩放 |
RKNN_dpu_ew_relux_cmp_value(0x407C)
EW RELUX 比较值。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | ew_relux_cmp_dat | EW RELUX 比较数据 |
RKNN_dpu_out_cvt_offset(0x4080)
输出转换偏移。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | out_cvt_offset | 输出转换器偏移 |
RKNN_dpu_out_cvt_scale(0x4084)
输出转换缩放 + fp32→fp16 使能。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:17 | RO | 0x0 | — | 保留 |
| 16 | RW | 0x0 | fp32tofp16_en | 使能输出 fp32→fp16 转换 |
| 15:0 | RW | 0x0 | out_cvt_scale | 输出转换器缩放 |
RKNN_dpu_out_cvt_shift(0x4088)
输出转换移位、舍入、指数。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31 | RW | 0x0 | cvt_type | 输出转换类型。0:先乘后加;1:先加后乘 |
| 30 | RW | 0x0 | cvt_round | 输出转换舍入。0:奇入偶不入;1:0.5 向上进 1 |
| 29:20 | RO | 0x0 | — | 保留 |
| 19:12 | RW | 0x0 | minus_exp | 输出 CVT 减指数 |
| 11:0 | RW | 0x0 | out_cvt_shift | 输出转换器移位 |
RKNN_dpu_ew_op_value_0~7(0x4090 ~ 0x40AC)
EW CORE 操作数寄存器,共 8 个,偏移 0x4090 + N×4(N = 0~7)。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | ew_operand_N | 第 N+1 个 EW 操作数 |
RKNN_dpu_surface_add(0x40C0)
Surface 加法器。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:4 | RW | 0x0 | surf_add | 一行中有多少个 surface |
| 3:0 | RO | 0x0 | — | 保留 |
RKNN_dpu_lut_access_cfg(0x4100)
LUT 访问配置。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:18 | RO | 0x0 | — | 保留 |
| 17 | RW | 0x0 | lut_access_type | 访问类型。0:读;1:写 |
| 16 | RW | 0x0 | lut_table_id | 访问 ID。0:LE LUT;1:LO LUT |
| 15:10 | RO | 0x0 | — | 保留 |
| 9:0 | RW | 0x0 | lut_addr | 访问地址 |
RKNN_dpu_lut_access_data(0x4104)
LUT 访问数据。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:16 | RO | 0x0 | — | 保留 |
| 15:0 | RW | 0x0 | lut_access_data | LUT 访问数据 |
RKNN_dpu_lut_cfg(0x4108)
LUT 配置。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:8 | RO | 0x0 | — | 保留 |
| 7 | RW | 0x0 | lut_cal_sel | LUT 计算选择(仅 lut_expand_en=1 时有效) |
| 6 | RW | 0x0 | lut_hybrid_priority | 混合流优先级。0:LE LUT;1:LO LUT |
| 5 | RW | 0x0 | lut_oflow_priority | 上溢优先级。0:LE;1:LO |
| 4 | RW | 0x0 | lut_uflow_priority | 下溢优先级。0:LE;1:LO |
| 3:2 | RW | 0x0 | lut_lo_le_mux | LO/LE LUT 复用 |
| 1 | RW | 0x0 | lut_expand_en | 扩展两个小 LUT 为一个大 LUT |
| 0 | RW | 0x0 | lut_road_sel | LUT 路径选择。0:第 1 路;1:第 2 路 |
RKNN_dpu_lut_info(0x410C)
LUT 索引选择。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:24 | RO | 0x0 | — | 保留 |
| 23:16 | RW | 0x0 | lut_lo_index_select | LO LUT 索引选择(索引生成器中选择哪些位作为索引) |
| 15:8 | RW | 0x0 | lut_le_index_select | LE LUT 索引选择 |
| 7:0 | RO | 0x0 | — | 保留 |
RKNN_dpu_lut_le_start(0x4110)
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | lut_le_start | LE LUT 起始点 |
RKNN_dpu_lut_le_end(0x4114)
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | lut_le_end | LE LUT 终止点 |
RKNN_dpu_lut_lo_start(0x4118)
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | lut_lo_start | LO LUT 起始点 |
RKNN_dpu_lut_lo_end(0x411C)
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | lut_lo_end | LO LUT 终止点 |
RKNN_dpu_lut_le_slope_scale(0x4120)
LE LUT 斜率缩放(上溢/下溢)。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:16 | RW | 0x0 | lut_le_slope_oflow_scale | LE LUT 上溢斜率缩放 |
| 15:0 | RW | 0x0 | lut_le_slope_uflow_scale | LE LUT 下溢斜率缩放 |
RKNN_dpu_lut_le_slope_shift(0x4124)
LE LUT 斜率移位。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:10 | RO | 0x0 | — | 保留 |
| 9:5 | RW | 0x0 | lut_le_slope_oflow_shift | LE LUT 上溢斜率移位 |
| 4:0 | RW | 0x0 | lut_le_slope_uflow_shift | LE LUT 下溢斜率移位 |
RKNN_dpu_lut_lo_slope_scale(0x4128)
LO LUT 斜率缩放。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:16 | RW | 0x0 | lut_lo_slope_oflow_scale | LO LUT 上溢斜率缩放 |
| 15:0 | RW | 0x0 | lut_lo_slope_uflow_scale | LO LUT 下溢斜率缩放 |
RKNN_dpu_lut_lo_slope_shift(0x412C)
LO LUT 斜率移位。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:10 | RO | 0x0 | — | 保留 |
| 9:5 | RW | 0x0 | lut_lo_slope_oflow_shift | LO LUT 上溢斜率移位 |
| 4:0 | RW | 0x0 | lut_lo_slope_uflow_shift | LO LUT 下溢斜率移位 |
DPU_RDMA 寄存器块
基址:CORE_BASE + 0x5000 | 地址范围:0x5000 ~ 0x5FFF
来源:RK3588 TRM §36.4.3 Detail Registers Description
DPU_RDMA 负责为 DPU 从外部内存读取输入数据,包含四路 DMA 引擎:MRDMA(主数据)、BRDMA(BS 操作数)、NRDMA(BN 操作数)、ERDMA(EW 操作数)。
RKNN_dpu_rdma_s_status(0x5000)
执行器状态寄存器(只读)。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:18 | RO | 0x0 | — | 保留 |
| 17:16 | RO | 0x0 | status_1 | 执行器 1 状态。0:空闲;1:正在执行;2:正在执行且等待执行;3:保留 |
| 15:2 | RO | 0x0 | — | 保留 |
| 1:0 | RO | 0x0 | status_0 | 执行器 0 状态。编码同 status_1 |
RKNN_dpu_rdma_s_pointer(0x5004)
寄存器组指针与 ping-pong 控制。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:17 | RO | 0x0 | — | 保留 |
| 16 | RO | 0x0 | executer | 当前使用的寄存器组。0:组 0;1:组 1 |
| 15:6 | RO | 0x0 | — | 保留 |
| 5 | W1C | 0x0 | executer_pp_clear | 清除执行器组指针,写 1 清零 |
| 4 | W1C | 0x0 | pointer_pp_clear | 清除寄存器组指针,写 1 清零 |
| 3 | RW | 0x0 | pointer_pp_mode | Ping-pong 模式。0:按执行器切换;1:按指针切换 |
| 2 | RW | 0x0 | executer_pp_en | 执行器组 ping-pong 使能 |
| 1 | RW | 0x0 | pointer_pp_en | 寄存器组 ping-pong 使能 |
| 0 | RW | 0x0 | pointer | 当前待设置的寄存器组。0:组 0;1:组 1 |
RKNN_dpu_rdma_operation_enable(0x5008)
操作使能。写入触发 DPU_RDMA 执行,此寄存器及之后均为 ping-pong 影子寄存器。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:1 | RO | 0x0 | — | 保留 |
| 0 | RW | 0x0 | op_en | DPU_RDMA 操作使能。0:禁用;1:使能 |
RKNN_dpu_rdma_data_cube_width(0x500C)
输入特征宽度。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:13 | RO | 0x0 | — | 保留 |
| 12:0 | RW | 0x0 | width | 输入特征宽度(需减 1) |
RKNN_dpu_rdma_data_cube_height(0x5010)
输入特征高度 + EW line notch。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:29 | RO | 0x0 | — | 保留 |
| 28:16 | RW | 0x0 | ew_line_notch_addr | EW 行 notch |
| 15:13 | RO | 0x0 | — | 保留 |
| 12:0 | RW | 0x0 | height | 输入特征高度(需减 1) |
RKNN_dpu_rdma_data_cube_channel(0x5014)
输入特征通道数。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:13 | RO | 0x0 | — | 保留 |
| 12:0 | RW | 0x0 | channel | 输入特征通道数(需减 1) |
RKNN_dpu_rdma_src_base_addr(0x5018)
Flying 模式源地址。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | src_base_addr | Flying 模式源地址 |
RKNN_dpu_rdma_brdma_cfg(0x501C)
BRDMA(BS 操作数读取 DMA)配置。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:5 | RO | 0x0 | — | 保留 |
| 4:1 | RW | 0x0 | brdma_data_use | 读取数据类型。[0]:ALU 操作数;[1]:CPEND 操作数;[2]:MUL 操作数;[3]:TRT 操作数 |
| 0 | RO | 0x0 | — | 保留 |
RKNN_dpu_rdma_bs_base_addr(0x5020)
BS 操作数基址。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | bs_base_addr | 读取 BS ALU、BS CPEND、BS MUL 操作数的基址 |
RKNN_dpu_rdma_nrdma_cfg(0x5028)
NRDMA(BN 操作数读取 DMA)配置。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:5 | RO | 0x0 | — | 保留 |
| 4:1 | RW | 0x0 | nrdma_data_use | 读取数据类型。[0]:ALU 操作数;[1]:CPEND 操作数(固定为 0,BN 无 CPEND);[2]:MUL 操作数;[3]:TRT 操作数 |
| 0 | RO | 0x0 | — | 保留 |
RKNN_dpu_rdma_bn_base_addr(0x502C)
BN 操作数基址。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | bn_base_addr | 读取 BN ALU、BN MUL 操作数的基址 |
RKNN_dpu_rdma_erdma_cfg(0x5034)
ERDMA(EW 操作数读取 DMA)配置。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:30 | RW | 0x0 | erdma_data_mode | 数据模式。0:按通道;1:按像素;2:按通道×像素;3:保留 |
| 29 | RW | 0x0 | erdma_surf_mode | Surface 模式。0:1 surface 串行;1:2 surface 串行 |
| 28 | RW | 0x0 | erdma_nonalign | 非对齐模式。0:禁用;1:使能 |
| 27:4 | RO | 0x0 | — | 保留 |
| 3:2 | RW | 0x0 | erdma_data_size | ERDMA 读取精度。0:4bit;1:8bit;2:16bit;3:32bit |
| 1 | RW | 0x0 | ov4k_bypass | 超 4K burst 拆分。0:使能;1:旁路 |
| 0 | RW | 0x0 | erdma_disable | 禁用 ERDMA。0:不禁用;1:禁用 |
RKNN_dpu_rdma_ew_base_addr(0x5038)
EW 操作数基址。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | ew_base_addr | 读取 EW 操作数的基址 |
RKNN_dpu_rdma_ew_surf_stride(0x5040)
EW 特征图 surface 步长。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:4 | RW | 0x0 | ew_surf_stride | EW 特征图 surface 步长。若 erdma_data_mode 为按通道模式,需设为 1 |
| 3:0 | RO | 0x0 | — | 保留 |
RKNN_dpu_rdma_feature_mode_cfg(0x5044)
特征模式配置:精度、burst、组合使用、flying mode、unpooling。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:18 | RO | 0x0 | — | 保留 |
| 17:15 | RW | 0x0 | in_precision | 输入数据精度。0:int8;1:int16;2:fp16;3:bf16;4:int32;5:fp32;6:int4 |
| 14:11 | RW | 0x0 | burst_len | Burst 长度。3:Burst4;7:Burst8;15:Burst16 |
| 10:8 | RW | 0x0 | comb_use | 组合使用。[0]:MRDMA 和 ERDMA 读同一数据;[1]:数据送 MRDMA;[2]:数据送 ERDMA |
| 7:5 | RW | 0x0 | proc_precision | 处理精度。编码同 in_precision |
| 4 | RW | 0x0 | mrdma_disable | 禁用 MRDMA。0:不禁用;1:禁用 |
| 3 | RW | 0x0 | mrdma_fp16tofp32_en | 使能 DPU 输入 fp16→fp32 转换 |
| 2:1 | RW | 0x0 | conv_mode | 卷积模式。0:DC;3:Depthwise |
| 0 | RW | 0x0 | flying_mode | Flying 模式。0:主数据来自卷积输出;1:主数据来自 MRDMA |
RKNN_dpu_rdma_src_dma_cfg(0x5048)
源 DMA 配置:line notch、unpooling 参数。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:19 | RW | 0x0 | line_notch_addr | 宽度末尾到 shape 特征行末的像素数 |
| 18:14 | RO | 0x0 | — | 保留 |
| 13 | RW | 0x0 | pooling_method | 池化方法。0:平均池化(上采样可用此模式);1:最小/最大池化 |
| 12 | RW | 0x0 | unpooling_en | 反池化使能 |
| 11:9 | RW | 0x0 | kernel_stride_height | 反池化 kernel 步长高度(−1) |
| 8:6 | RW | 0x0 | kernel_stride_width | 反池化 kernel 步长宽度(−1) |
| 5:3 | RW | 0x0 | kernel_height | 反池化 kernel 高度(−1) |
| 2:0 | RW | 0x0 | kernel_width | 反池化 kernel 宽度(−1) |
RKNN_dpu_rdma_surf_notch(0x504C)
Surface notch。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:4 | RW | 0x0 | surf_notch_addr | 当前处理特征图末尾到 shape 特征图末尾的像素数 |
| 3:0 | RO | 0x0 | — | 保留 |
RKNN_dpu_rdma_pad_cfg(0x5064)
反池化 Pad 配置。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:16 | RW | 0x0 | pad_value | Pad 填充值 |
| 15:7 | RO | 0x0 | — | 保留 |
| 6:4 | RW | 0x0 | pad_top | 反池化顶部 pad |
| 3 | RO | 0x0 | — | 保留 |
| 2:0 | RW | 0x0 | pad_left | 反池化左侧 pad |
RKNN_dpu_rdma_weight(0x5068)
四路 DMA 仲裁权重。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:24 | RW | 0x0 | e_weight | ERDMA 仲裁权重 |
| 23:16 | RW | 0x0 | n_weight | NRDMA 仲裁权重 |
| 15:8 | RW | 0x0 | b_weight | BRDMA 仲裁权重 |
| 7:0 | RW | 0x0 | m_weight | MRDMA 仲裁权重 |
RKNN_dpu_rdma_ew_surf_notch(0x506C)
EW surface notch。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:4 | RW | 0x0 | ew_surf_notch | EW surface notch |
| 3:0 | RO | 0x0 | — | 保留 |
PPU 寄存器块(Planar Processing Unit)
基址:CORE_BASE + 0x6000 | 地址范围:0x6000 ~ 0x6FFF
来源:RK3588 TRM §36.4.3 Detail Registers Description
PPU 负责池化运算,支持平均池化、最大池化、最小池化,可与 DPU 流水线级联或独立 flying 模式运行。
RKNN_ppu_s_status(0x6000)
执行器状态寄存器(只读)。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:18 | RO | 0x0 | — | 保留 |
| 17:16 | RO | 0x0 | status_1 | 执行器 1 状态。0:空闲;1:正在执行;2:正在执行且等待执行;3:保留 |
| 15:2 | RO | 0x0 | — | 保留 |
| 1:0 | RO | 0x0 | status_0 | 执行器 0 状态。编码同 status_1 |
RKNN_ppu_s_pointer(0x6004)
寄存器组指针与 ping-pong 控制。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:17 | RO | 0x0 | — | 保留 |
| 16 | RO | 0x0 | executer | 当前使用的寄存器组。0:组 0;1:组 1 |
| 15:6 | RO | 0x0 | — | 保留 |
| 5 | W1C | 0x0 | executer_pp_clear | 清除执行器组指针,写 1 清零 |
| 4 | W1C | 0x0 | pointer_pp_clear | 清除寄存器组指针,写 1 清零 |
| 3 | RW | 0x0 | pointer_pp_mode | Ping-pong 模式。0:按执行器切换;1:按指针切换 |
| 2 | RW | 0x0 | executer_pp_en | 执行器组 ping-pong 使能 |
| 1 | RW | 0x0 | pointer_pp_en | 寄存器组 ping-pong 使能 |
| 0 | RW | 0x0 | pointer | 当前待设置的寄存器组。0:组 0;1:组 1 |
RKNN_ppu_operation_enable(0x6008)
操作使能。写入触发 PPU 执行,此寄存器及之后均为 ping-pong 影子寄存器。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:1 | RO | 0x0 | — | 保留 |
| 0 | RW | 0x0 | op_en | PPU 操作使能。0:禁用;1:使能 |
RKNN_ppu_data_cube_in_width(0x600C)
池化输入 cube 宽度。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:13 | RO | 0x0 | — | 保留 |
| 12:0 | RW | 0x0 | cube_in_width | 池化输入宽度(需减 1) |
RKNN_ppu_data_cube_in_height(0x6010)
池化输入 cube 高度。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:13 | RO | 0x0 | — | 保留 |
| 12:0 | RW | 0x0 | cube_in_height | 池化输入高度(需减 1) |
RKNN_ppu_data_cube_in_channel(0x6014)
池化输入 cube 通道数。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:13 | RO | 0x0 | — | 保留 |
| 12:0 | RW | 0x0 | cube_in_channel | 池化输入通道数(需减 1) |
RKNN_ppu_data_cube_out_width(0x6018)
池化输出 cube 宽度。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:13 | RO | 0x0 | — | 保留 |
| 12:0 | RW | 0x0 | cube_out_width | 池化输出宽度(需减 1) |
RKNN_ppu_data_cube_out_height(0x601C)
池化输出 cube 高度。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:13 | RO | 0x0 | — | 保留 |
| 12:0 | RW | 0x0 | cube_out_height | 池化输出高度(需减 1) |
RKNN_ppu_data_cube_out_channel(0x6020)
池化输出 cube 通道数。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:13 | RO | 0x0 | — | 保留 |
| 12:0 | RW | 0x0 | cube_out_channel | 池化输出通道数(需减 1) |
RKNN_ppu_operation_mode_cfg(0x6024)
操作模式配置:池化方法、flying mode、notch、索引输出。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31 | RO | 0x0 | — | 保留 |
| 30 | RW | 0x0 | index_en | 使能输出每个 kernel 的位置索引 |
| 29 | RO | 0x0 | — | 保留 |
| 28:16 | RW | 0x0 | notch_addr | 宽度末尾到 shape 行末的像素数 |
| 15:8 | RO | 0x0 | — | 保留 |
| 7:5 | RW | 0x0 | use_cnt | use_cnt |
| 4 | RW | 0x0 | flying_mode | 池化 cube 来源。0:DPU;1:外部 |
| 3:2 | RO | 0x0 | — | 保留 |
| 1:0 | RW | 0x0 | pooling_method | 池化方法。0:平均池化;1:最大池化;2:最小池化;3:保留 |
RKNN_ppu_pooling_kernel_cfg(0x6034)
池化 kernel 大小与步长。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:24 | RO | 0x0 | — | 保留 |
| 23:20 | RW | 0x0 | kernel_stride_height | Kernel 步长高度(需减 1) |
| 19:16 | RW | 0x0 | kernel_stride_width | Kernel 步长宽度(需减 1) |
| 15:12 | RO | 0x0 | — | 保留 |
| 11:8 | RW | 0x0 | kernel_height | Kernel 高度(需减 1) |
| 7:4 | RO | 0x0 | — | 保留 |
| 3:0 | RW | 0x0 | kernel_width | Kernel 宽度(需减 1) |
RKNN_ppu_recip_kernel_width(0x6038)
Kernel 宽度倒数(用于平均池化计算)。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:17 | RO | 0x0 | — | 保留 |
| 16:0 | RW | 0x0 | recip_kernel_width | Shape kernel 宽度的倒数 × 2^16 |
RKNN_ppu_recip_kernel_height(0x603C)
Kernel 高度倒数。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:17 | RO | 0x0 | — | 保留 |
| 16:0 | RW | 0x0 | recip_kernel_height | Shape kernel 高度的倒数 × 2^16 |
RKNN_ppu_pooling_padding_cfg(0x6040)
池化四边 padding。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:15 | RO | 0x0 | — | 保留 |
| 14:12 | RW | 0x0 | pad_bottom | 底部 pad |
| 11 | RO | 0x0 | — | 保留 |
| 10:8 | RW | 0x0 | pad_right | 右侧 pad |
| 7 | RO | 0x0 | — | 保留 |
| 6:4 | RW | 0x0 | pad_top | 顶部 pad |
| 3 | RO | 0x0 | — | 保留 |
| 2:0 | RW | 0x0 | pad_left | 左侧 pad |
RKNN_ppu_padding_value_1_cfg(0x6044)
Pad 填充值低 32 位。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | pad_value_0 | pad_value×1 [31:0] |
RKNN_ppu_padding_value_2_cfg(0x6048)
Pad 填充值高 3 位。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:3 | RO | 0x0 | — | 保留 |
| 2:0 | RW | 0x0 | pad_value_1 | pad_value×1 [34:32] |
RKNN_ppu_dst_base_addr(0x6070)
输出 cube 目标基址。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:4 | RW | 0x0 | dst_base_addr | 输出 cube 目标基址 |
| 3:0 | RO | 0x0 | — | 保留 |
RKNN_ppu_dst_surf_stride(0x607C)
输出 surface 步长。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:4 | RW | 0x0 | dst_surf_stride | 输出 shape 面积 |
| 3:0 | RO | 0x0 | — | 保留 |
RKNN_ppu_data_format(0x6084)
数据格式配置。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:4 | RW | 0x0 | index_add | 若 index_en 使能,值为 dst_surface_stride × cube surface 数(每 surface 8 字节),否则等于 dst_surface_stride |
| 3 | RW | 0x0 | dpu_flyin | 数据来自 DPU 且 DPU 数据来自外部时置 1 |
| 2:0 | RW | 0x0 | proc_precision | 处理精度 |
RKNN_ppu_misc_ctrl(0x60DC)
杂项控制:非对齐模式、多 surface 输出、burst。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:16 | RW | 0x0 | surf_len | Surface 计数长度 |
| 15:9 | RO | 0x0 | — | 保留 |
| 8 | RW | 0x0 | mc_surf_out | 多 surface 输出使能 |
| 7 | RW | 0x0 | nonalign | 非对齐模式使能 |
| 6:4 | RO | 0x0 | — | 保留 |
| 3:0 | RW | 0x0 | burst_len | Burst 长度。3:Burst4;7:Burst8;15:Burst16 |
PPU_RDMA 寄存器块
基址:CORE_BASE + 0x7000 | 地址范围:0x7000 ~ 0x7FFF
来源:RK3588 TRM §36.4.3 Detail Registers Description
PPU_RDMA 负责为 PPU 从外部内存读取池化输入特征数据(flying 模式下使用)。
RKNN_ppu_rdma_s_status(0x7000)
执行器状态寄存器(只读)。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:18 | RO | 0x0 | — | 保留 |
| 17:16 | RO | 0x0 | status_1 | 执行器 1 状态。0:空闲;1:正在执行;2:正在执行且等待执行;3:保留 |
| 15:2 | RO | 0x0 | — | 保留 |
| 1:0 | RO | 0x0 | status_0 | 执行器 0 状态。编码同 status_1 |
RKNN_ppu_rdma_s_pointer(0x7004)
寄存器组指针与 ping-pong 控制。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:17 | RO | 0x0 | — | 保留 |
| 16 | RO | 0x0 | executer | 当前使用的寄存器组。0:组 0;1:组 1 |
| 15:6 | RO | 0x0 | — | 保留 |
| 5 | W1C | 0x0 | executer_pp_clear | 清除执行器组指针,写 1 清零 |
| 4 | W1C | 0x0 | pointer_pp_clear | 清除寄存器组指针,写 1 清零 |
| 3 | RW | 0x0 | pointer_pp_mode | Ping-pong 模式。0:按执行器切换;1:按指针切换 |
| 2 | RW | 0x0 | executer_pp_en | 执行器组 ping-pong 使能 |
| 1 | RW | 0x0 | pointer_pp_en | 寄存器组 ping-pong 使能 |
| 0 | RW | 0x0 | pointer | 当前待设置的寄存器组。0:组 0;1:组 1 |
RKNN_ppu_rdma_operation_enable(0x7008)
操作使能。写入触发 PPU_RDMA 执行,此寄存器及之后均为 ping-pong 影子寄存器。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:1 | RO | 0x0 | — | 保留 |
| 0 | RW | 0x0 | op_en | PPU_RDMA 操作使能。0:禁用;1:使能 |
RKNN_ppu_rdma_cube_in_width(0x700C)
池化输入 cube 宽度。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:13 | RO | 0x0 | — | 保留 |
| 12:0 | RW | 0x0 | cube_in_width | 池化 cube 宽度(需减 1) |
RKNN_ppu_rdma_cube_in_height(0x7010)
池化输入 cube 高度。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:13 | RO | 0x0 | — | 保留 |
| 12:0 | RW | 0x0 | cube_in_height | 池化 cube 高度(需减 1) |
RKNN_ppu_rdma_cube_in_channel(0x7014)
池化输入 cube 通道数。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:13 | RO | 0x0 | — | 保留 |
| 12:0 | RW | 0x0 | cube_in_channel | 池化 cube 通道数(需减 1) |
RKNN_ppu_rdma_src_base_addr(0x701C)
池化 cube 源基址。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | src_base_addr | 池化 cube 基址 |
RKNN_ppu_rdma_src_line_stride(0x7024)
源行步长(shape 宽度)。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:4 | RW | 0x0 | src_line_stride | 池化 cube shape 宽度 |
| 3:0 | RO | 0x0 | — | 保留 |
RKNN_ppu_rdma_src_surf_stride(0x7028)
源 surface 步长(shape 面积)。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:4 | RW | 0x0 | src_surf_stride | 池化 cube shape 面积 |
| 3:0 | RO | 0x0 | — | 保留 |
RKNN_ppu_rdma_data_format(0x7030)
输入数据格式。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:2 | RO | 0x0 | — | 保留 |
| 1:0 | RW | 0x0 | in_precision | 输入精度。0:4bit;1:8bit;2:16bit;3:32bit |
DDMA / SDMA 寄存器块(Data DMA / System DMA)
DDMA 基址:CORE_BASE + 0x8000 | 地址范围:0x8000 ~ 0x8FFF
SDMA 基址:CORE_BASE + 0x9000 | 地址范围:0x9000 ~ 0x9FFF
来源:RK3588 TRM §36.4.3 Detail Registers Description
DDMA 和 SDMA 寄存器布局完全一致,仅基址不同(DDMA 0x8xxx,SDMA 0x9xxx)。DDMA 用于数据搬运,SDMA 用于系统级搬运。以下以 DDMA 为例展开位域,SDMA 将偏移 0x8xxx 替换为 0x9xxx 即可。
cfg_outstanding(DDMA: 0x8000 / SDMA: 0x9000)
读写 outstanding 数配置。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:16 | RO | 0x0 | — | 保留 |
| 15:8 | RW | 0x0 | wr_os_cnt | 最大写 outstanding 数 |
| 7:0 | RW | 0x0 | rd_os_cnt | 最大读 outstanding 数 |
rd_weight_0(DDMA: 0x8004 / SDMA: 0x9004)
读仲裁权重 0:各模块读 burst 权重。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:24 | RW | 0x0 | rd_weight_pdp | PPU 读 burst 权重 |
| 23:16 | RW | 0x0 | rd_weight_dpu | DPU 读 burst 权重 |
| 15:8 | RW | 0x0 | rd_weight_kernel | 权重读 burst 权重 |
| 7:0 | RW | 0x0 | rd_weight_feature | 特征读 burst 权重 |
wr_weight_0(DDMA: 0x8008 / SDMA: 0x9008)
写仲裁权重。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:16 | RO | 0x0 | — | 保留 |
| 15:8 | RW | 0x0 | wr_weight_pdp | PPU 写权重 |
| 7:0 | RW | 0x0 | wr_weight_dpu | DPU 写权重 |
cfg_id_error(DDMA: 0x800C / SDMA: 0x900C)
错误 ID 记录。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:10 | RO | 0x0 | — | 保留 |
| 9:6 | RW | 0x0 | wr_resp_id | 错误写 ID |
| 5 | RO | 0x0 | — | 保留 |
| 4:0 | RW | 0x0 | rd_resp_id | 错误读 ID |
rd_weight_1(DDMA: 0x8010 / SDMA: 0x9010)
读仲裁权重 1:PC 读 burst 权重。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:8 | RO | 0x0 | — | 保留 |
| 7:0 | RW | 0x0 | rd_weight_pc | PC 读 burst 权重 |
cfg_dma_fifo_clr(DDMA: 0x8014 / SDMA: 0x9014)
清除 DMA FIFO。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:1 | RO | 0x0 | — | 保留 |
| 0 | RW | 0x0 | dma_fifo_clr | 清除 DMA FIFO |
cfg_dma_arb(DDMA: 0x8018 / SDMA: 0x9018)
DMA 仲裁模式配置。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:10 | RO | 0x0 | — | 保留 |
| 9 | RW | 0x0 | wr_arbit_model | 写仲裁模型 |
| 8 | RW | 0x0 | rd_arbit_model | 读仲裁模型 |
| 7 | RO | 0x0 | — | 保留 |
| 6:4 | RW | 0x0 | wr_fix_arb | 写固定仲裁 |
| 3 | RO | 0x0 | — | 保留 |
| 2:0 | RW | 0x0 | rd_fix_arb | 读固定仲裁 |
cfg_dma_rd_qos(DDMA: 0x8020 / SDMA: 0x9020)
各模块读 QoS 配置。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:10 | RO | 0x0 | — | 保留 |
| 9:8 | RW | 0x0 | rd_pc_qos | PC 读 QoS |
| 7:6 | RW | 0x0 | rd_ppu_qos | PPU 读 QoS |
| 5:4 | RW | 0x0 | rd_dpu_qos | DPU 读 QoS |
| 3:2 | RW | 0x0 | rd_kernel_qos | Kernel 读 QoS |
| 1:0 | RW | 0x0 | rd_feature_qos | Feature 读 QoS |
cfg_dma_rd_cfg(DDMA: 0x8024 / SDMA: 0x9024)
AXI 读通道信号配置。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:13 | RO | 0x0 | — | 保留 |
| 12 | RW | 0x0 | rd_arlock | AXI arlock |
| 11:8 | RW | 0x0 | rd_arcache | AXI arcache |
| 7:5 | RW | 0x0 | rd_arprot | AXI arprot |
| 4:3 | RW | 0x0 | rd_arburst | AXI arburst |
| 2:0 | RW | 0x0 | rd_arsize | AXI arsize |
cfg_dma_wr_cfg(DDMA: 0x8028 / SDMA: 0x9028)
AXI 写通道信号配置。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:13 | RO | 0x0 | — | 保留 |
| 12 | RW | 0x0 | wr_awlock | AXI awlock |
| 11:8 | RW | 0x0 | wr_awcache | AXI awcache |
| 7:5 | RW | 0x0 | wr_awprot | AXI awprot |
| 4:3 | RW | 0x0 | wr_awburst | AXI awburst |
| 2:0 | RW | 0x0 | wr_awsize | AXI awsize |
cfg_dma_wstrb(DDMA: 0x802C / SDMA: 0x902C)
AXI 写选通。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RW | 0x0 | wr_wstrb | AXI 写选通信号 |
cfg_status(DDMA: 0x8030 / SDMA: 0x9030)
DMA 状态。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:9 | RO | 0x0 | — | 保留 |
| 8 | RW | 0x0 | idel | 空闲状态 |
| 7:0 | RO | 0x0 | — | 保留 |
dt_wr_amount(DDMA: 0x8034 / SDMA: 0x9034)
数据写入量统计。用于 ioctl GetDtWrAmount。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RO | 0x0 | dt_wr_amount | 数据写入量 |
dt_rd_amount(DDMA: 0x8038 / SDMA: 0x9038)
数据读取量统计。用于 ioctl GetDtRdAmount。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RO | 0x0 | dt_rd_amount | 数据读取量 |
wt_rd_amount(DDMA: 0x803C / SDMA: 0x903C)
权重读取量统计。用于 ioctl GetWtRdAmount。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:0 | RO | 0x0 | wt_rd_amount | 权重读取量 |
清除操作:写
rd_weight_1(0x8010) 值0x80000101再写0x00000101(两次写入进行 latch/clear)。
GLOBAL 寄存器块(全局使能)
基址:CORE_BASE + 0xF000 | 地址范围:0xF000 ~ 0xFFFF
来源:RK3588 TRM §36.4.3 Detail Registers Description
GLOBAL 模块仅包含一个寄存器,用于一次性组合使能各功能模块的操作。
RKNN_global_operation_enable(0xF008)
组合操作使能:一次写入同时触发多个模块开始执行。
| Bit | 属性 | 复位值 | 字段名 | 描述 |
|---|---|---|---|---|
| 31:7 | RO | 0x0 | — | 保留 |
| 6 | RW | 0x0 | ppu_rdma_op_en | PPU_RDMA 操作使能 |
| 5 | RW | 0x0 | ppu_op_en | PPU 操作使能 |
| 4 | RW | 0x0 | dpu_rdma_op_en | DPU_RDMA 操作使能 |
| 3 | RW | 0x0 | dpu_op_en | DPU 操作使能 |
| 2 | RW | 0x0 | core_op_en | CORE 操作使能 |
| 1 | RO | 0x0 | — | 保留 |
| 0 | RW | 0x0 | cna_op_en | CNA 操作使能 |
IOCTL 协议与数据结构
本章整理 RKNPU 驱动的全部 ioctl 命令、传参结构体布局、flags 枚举,以及 mmap(offset) 编码规则。
1. IOCTL 命令表
RKNPU 驱动提供 6 个 ioctl 命令,同时定义了两套编号:
| 命令 | 编号 | DRM 路径宏 | 非 DRM 路径宏 | 方向 | 结构体 | 功能 |
|---|---|---|---|---|---|---|
| ACTION | 0x00 |
DRM_IOCTL_RKNPU_ACTION |
IOCTL_RKNPU_ACTION |
IOWR | rknpu_action |
查询/设置:版本、频率、电压、电源、统计、复位等 |
| SUBMIT | 0x01 |
DRM_IOCTL_RKNPU_SUBMIT |
IOCTL_RKNPU_SUBMIT |
IOWR | rknpu_submit |
提交 NPU 任务(PC job) |
| MEM_CREATE | 0x02 |
DRM_IOCTL_RKNPU_MEM_CREATE |
IOCTL_RKNPU_MEM_CREATE |
IOWR | rknpu_mem_create |
分配 DMA buffer(GEM 对象) |
| MEM_MAP | 0x03 |
DRM_IOCTL_RKNPU_MEM_MAP |
IOCTL_RKNPU_MEM_MAP |
IOWR | rknpu_mem_map |
获取 mmap 用的 fake offset |
| MEM_DESTROY | 0x04 |
DRM_IOCTL_RKNPU_MEM_DESTROY |
IOCTL_RKNPU_MEM_DESTROY |
IOWR | rknpu_mem_destroy |
释放 DMA buffer |
| MEM_SYNC | 0x05 |
DRM_IOCTL_RKNPU_MEM_SYNC |
IOCTL_RKNPU_MEM_SYNC |
IOWR | rknpu_mem_sync |
Cache 同步(flush / invalidate) |
1.1 两套编号的区别
| DRM 路径 | 非 DRM 路径 | |
|---|---|---|
| 编码方式 | DRM_IOWR(DRM_COMMAND_BASE + nr, type) |
_IOWR('r', nr, type) |
| 设备节点 | /dev/dri/cardX |
/dev/rknpu(如果驱动注册了) |
| 调用方式 | drmIoctl(fd, DRM_IOCTL_RKNPU_*, &arg) |
ioctl(fd, IOCTL_RKNPU_*, &arg) |
| 闭源库使用 | librknnrt.so 主要走此路径 |
备选 |
rknpu-ioctl.h 中
RKNPU_IOC_MAGIC = 'r',DRM_COMMAND_BASE来自<libdrm/drm.h>(通常为0x40)。
2. 结构体布局
2.1 struct rknpu_action(8 字节)
用于 ACTION ioctl,查询/设置各种属性。
| 偏移 | 大小 | 类型 | 字段 | 说明 |
|---|---|---|---|---|
0x00 | 4 | __u32 | flags | Action 编号(见 §3.4) |
0x04 | 4 | __u32 | value | GET 时为返回值,SET 时为输入值 |
2.2 struct rknpu_mem_create(40 字节)
| 偏移 | 大小 | 类型 | 字段 | 方向 | 说明 |
|---|---|---|---|---|---|
0x00 | 4 | __u32 | handle | OUT | GEM 对象句柄(驱动分配) |
0x04 | 4 | __u32 | flags | IN | 内存类型 flags(见 §3.1) |
0x08 | 8 | __u64 | size | IN | 申请大小(内部页对齐) |
0x10 | 8 | __u64 | obj_addr | OUT | 内核对象地址(opaque token) |
0x18 | 8 | __u64 | dma_addr | OUT | 设备侧 DMA 地址(IOVA 或物理地址) |
0x20 | 8 | __u64 | sram_size | IN | 可选 SRAM 申请大小 |
StarryOS Rust 驱动 扩展了额外字段:
iommu_domain_id: i32、core_mask: u32,用于多核/IOMMU 域管理。
2.3 struct rknpu_mem_map(16 字节)
| 偏移 | 大小 | 类型 | 字段 | 方向 | 说明 |
|---|---|---|---|---|---|
0x00 | 4 | __u32 | handle | IN | GEM 句柄 |
0x04 | 4 | __u32 | reserved | — | 64 位对齐填充 |
0x08 | 8 | __u64 | offset | OUT | fake offset,用于 mmap(fd, ..., offset) |
2.4 struct rknpu_mem_destroy(16 字节)
| 偏移 | 大小 | 类型 | 字段 | 方向 | 说明 |
|---|---|---|---|---|---|
0x00 | 4 | __u32 | handle | IN | GEM 句柄 |
0x04 | 4 | __u32 | reserved | — | 填充 |
0x08 | 8 | __u64 | obj_addr | IN | 内核对象地址 |
2.5 struct rknpu_mem_sync(32 字节)
| 偏移 | 大小 | 类型 | 字段 | 方向 | 说明 |
|---|---|---|---|---|---|
0x00 | 4 | __u32 | flags | IN | 同步方向(见 §3.2) |
0x04 | 4 | __u32 | reserved | — | 填充 |
0x08 | 8 | __u64 | obj_addr | IN | 要同步的内核对象地址 |
0x10 | 8 | __u64 | offset | IN | 同步起始偏移(字节) |
0x18 | 8 | __u64 | size | IN | 同步区域大小 |
2.6 struct rknpu_task(36 字节,__packed)
单个任务描述,由 PC 命令流引擎解释执行。
| 偏移 | 大小 | 类型 | 字段 | 说明 |
|---|---|---|---|---|
0x00 | 4 | __u32 | flags | 任务标志 |
0x04 | 4 | __u32 | op_idx | 算子索引 |
0x08 | 4 | __u32 | enable_mask | 模块使能掩码 |
0x0C | 4 | __u32 | int_mask | 期望的完成中断掩码 |
0x10 | 4 | __u32 | int_clear | 中断清除值 |
0x14 | 4 | __u32 | int_status | 完成后驱动写回实际中断状态 |
0x18 | 4 | __u32 | regcfg_amount | 寄存器配置项数量 |
0x1C | 4 | __u32 | regcfg_offset | 寄存器配置在命令流中的偏移 |
0x20 | 8 | __u64 | regcmd_addr | 寄存器命令流 DMA 地址 |
__packed:编译器不插入 padding,保证与内核侧布局一致。
2.7 struct rknpu_subcore_task(8 字节)
| 偏移 | 大小 | 类型 | 字段 | 说明 |
|---|---|---|---|---|
0x00 | 4 | __u32 | task_start | 该子核心的起始 task 索引 |
0x04 | 4 | __u32 | task_number | 该子核心要执行的 task 数量 |
2.8 struct rknpu_submit(96 字节)
任务提交主结构体,驱动最核心的入口。
| 偏移 | 大小 | 类型 | 字段 | 说明 |
|---|---|---|---|---|
0x00 | 4 | __u32 | flags | Job 模式(见 §3.3) |
0x04 | 4 | __u32 | timeout | 超时时间(ms) |
0x08 | 4 | __u32 | task_start | 全局起始 task 索引 |
0x0C | 4 | __u32 | task_number | 全局 task 数量 |
0x10 | 4 | __u32 | task_counter | 计数/序列号 |
0x14 | 4 | __s32 | priority | 调度优先级 |
0x18 | 8 | __u64 | task_obj_addr | task 数组的内核对象地址 |
0x20 | 8 | __u64 | regcfg_obj_addr | 寄存器配置对象地址 |
0x28 | 8 | __u64 | task_base_addr | task 基址(设备侧) |
0x30 | 8 | __u64 | user_data | 可选用户数据(透传/调试) |
0x38 | 4 | __u32 | core_mask | 核心选择掩码(bit0=core0, bit1=core1, bit2=core2) |
0x3C | 4 | __s32 | fence_fd | dma-fence fd(IN: fence_in, OUT: fence_out) |
0x40 | 40 | subcore_task[5] | subcore_task | 5 组子核心任务分配 |
StarryOS Rust 驱动 变体:将
regcfg_obj_addr替换为iommu_domain_id+reserved,并增加hw_elapse_time字段。
3. Flags 枚举
3.1 enum e_rknpu_mem_type(内存类型,位掩码)
| 值 | 名称 | 说明 |
|---|---|---|
0 << 0 | CONTIGUOUS | 物理连续(默认) |
1 << 0 | NON_CONTIGUOUS | 物理不连续 |
0 << 1 | NON_CACHEABLE | 不可缓存(默认) |
1 << 1 | CACHEABLE | 可缓存 |
1 << 2 | WRITE_COMBINE | Write-Combine 映射 |
1 << 3 | KERNEL_MAPPING | 内核态映射 |
1 << 4 | IOMMU | IOMMU 映射 |
1 << 5 | ZEROING | 分配后清零 |
1 << 6 | SECURE | 安全内存 |
1 << 7 | NON_DMA32 | 不限于 DMA32 区域 |
1 << 8 | TRY_ALLOC_SRAM | 尝试分配 SRAM |
MEM_MASK = 0x1FF(bit0~bit8 的合法组合集)
3.2 enum e_rknpu_mem_sync_mode(Cache 同步方向)
| 值 | 名称 | 说明 |
|---|---|---|
1 << 0 | SYNC_TO_DEVICE | CPU → 设备:flush cache |
1 << 1 | SYNC_FROM_DEVICE | 设备 → CPU:invalidate cache |
3.3 enum e_rknpu_job_mode(Job 模式,位掩码)
| 值 | 名称 | 说明 |
|---|---|---|
0 << 0 | SLAVE | 从模式(默认) |
1 << 0 | PC | PC(Program Counter)模式 |
0 << 1 | BLOCK | 阻塞等待完成(默认) |
1 << 1 | NONBLOCK | 非阻塞返回 |
1 << 2 | PINGPONG | 双缓冲/流水模式 |
1 << 3 | FENCE_IN | 等待输入 fence |
1 << 4 | FENCE_OUT | 返回输出 fence fd |
3.4 enum e_rknpu_action(Action 编号)
| 编号 | 名称 | 方向 | 说明 |
|---|---|---|---|
| 0 | GET_HW_VERSION | GET | 读取硬件版本 |
| 1 | GET_DRV_VERSION | GET | 读取驱动版本(编码:major*10000+minor*100+patch) |
| 2 | GET_FREQ | GET | 读取当前频率 |
| 3 | SET_FREQ | SET | 设置频率 |
| 4 | GET_VOLT | GET | 读取电压 |
| 5 | SET_VOLT | SET | 设置电压 |
| 6 | ACT_RESET | ACT | NPU 软复位 |
| 7 | GET_BW_PRIORITY | GET | 带宽优先级 |
| 8 | SET_BW_PRIORITY | SET | 设置带宽优先级 |
| 9 | GET_BW_EXPECT | GET | 期望带宽 |
| 10 | SET_BW_EXPECT | SET | 设置期望带宽 |
| 11 | GET_BW_TW | GET | 带宽时间窗 |
| 12 | SET_BW_TW | SET | 设置带宽时间窗 |
| 13 | ACT_CLR_TOTAL_RW_AMOUNT | ACT | 清除读写量统计 |
| 14 | GET_DT_WR_AMOUNT | GET | 数据写入量 |
| 15 | GET_DT_RD_AMOUNT | GET | 数据读取量 |
| 16 | GET_WT_RD_AMOUNT | GET | 权重读取量 |
| 17 | GET_TOTAL_RW_AMOUNT | GET | 总读写量 |
| 18 | GET_IOMMU_EN | GET | IOMMU 是否启用 |
| 19 | SET_PROC_NICE | SET | 进程优先级 |
| 20 | POWER_ON | ACT | NPU 上电 |
| 21 | POWER_OFF | ACT | NPU 下电 |
| 22 | GET_TOTAL_SRAM_SIZE | GET | SRAM 总大小 |
| 23 | GET_FREE_SRAM_SIZE | GET | SRAM 空闲大小 |
| 24 | GET_IOMMU_DOMAIN_ID | GET | StarryOS 扩展 |
| 25 | SET_IOMMU_DOMAIN_ID | SET | StarryOS 扩展 |
4. mmap 规则(handle → offset 编码)
4.1 流程
sequenceDiagram
participant U as 用户态
participant K as 内核驱动
U->>K: ioctl(MEM_CREATE, {size, flags})
K-->>U: {handle, obj_addr, dma_addr}
U->>K: ioctl(MEM_MAP, {handle})
K-->>U: {offset}
U->>U: ptr = mmap(fd, size, PROT_RW, MAP_SHARED, fd, offset)
Note over U: 现在 ptr 指向 DMA buffer 的用户态映射
U->>K: ioctl(MEM_SYNC, {obj_addr, offset=0, size, flags=TO_DEVICE})
Note over K: flush CPU cache → 设备可见
Note over U,K: ... 使用 buffer(填充数据 / 读取结果)...
U->>K: ioctl(MEM_DESTROY, {handle, obj_addr})
Note over K: 释放 GEM 对象 + DMA 内存
4.2 offset 编码约定
Linux rknpu 驱动 中,MEM_MAP 返回的 offset 是 DRM GEM 的 fake offset:
- 由
drm_gem_create_mmap_offset()生成 - 编码方式:
offset = handle_to_node_offset(DRM 内部维护的映射表) - 用户态拿到
offset后,传给mmap()的最后一个参数 - 内核在
drm_gem_mmap()中根据 offset 查找对应的 GEM 对象,建立页表映射
StarryOS 实现:由于没有完整 DRM 框架,需要自行维护 handle → 物理页的映射表,并在
sys_mmap的DeviceMmap::Physical路径中完成映射。
4.3 对齐要求
size:内部页对齐(4KB)offset:必须页对齐dma_addr:取决于是否启用 IOMMU- 有 IOMMU:返回 IOVA(设备虚拟地址)
- 无 IOMMU:返回物理地址(需物理连续)
当前提交-IRQ 边界快照恢复系统
当前 NPU 队列调度器配合说明
这份文档讲的是当前这版 NPU 调度链路到底怎么配合。重点不是复盘历史方案,而是把已经落到代码里的职责边界讲清楚:card1 做什么,StarryOS 里的 scheduler 做什么,驱动和 IRQ 路径现在只剩下什么责任,以及一次 Submit 是怎么从入队一路走到返回用户态的。
这版实现保留了一个很明确的核心模型:
- 对外还是阻塞
Submitioctl - 对内是一整次 submit 入队
- 真正下发给硬件时是 per-core、per-task streaming dispatch
- 每个 submit 自己有 waiter
- 全局只有一个 kick,用来唤醒 worker
- in-flight dispatch 的 owner 只保留在 scheduler 一处
所以从用户态看,语义没变;从内核实现看,控制流已经不是“调用线程自己 loop 推完整次 submit”了,而是“调用线程阻塞,后台 worker 负责推进和补发”。
1. 先说结论
当前链路可以概括成四句话:
- 用户线程发起
Submit,card1先把RknpuSubmit和RknpuTask[]拷到内核 shadow。 - 整次 submit 作为一个队列项入队,但真正发给硬件时是按 core、按 task 一次一次地下发。
- 哪个 core 先完成,就先 harvest 哪个 core,再尽快给它补下一个可运行 task。
- 原始提交线程睡在自己的 waiter 上,等 submit 进入 terminal 状态后被唤醒,再把最终结果拷回用户态。
这就是“阻塞 submit + 内部异步调度”的准确含义。
2. 为什么要收成现在这个形状
之前的问题主要有两个。
第一个问题是职责缠在一起。card1 既处理 ioctl,又自己循环推进 task,还要主动 yield_now() 给别的执行流机会。路径长,问题一多就很难沿着职责边界查。
第二个问题是内部状态太散。一份 submit 的信息会在 card1 / scheduler / queue / driver 之间换着名字存几次;in-flight dispatch 也会在 queue 和 driver 两边都留一份反向绑定,最后软件模型比真正需要的边界还重。
所以现在的收口原则很直接:
RknpuSubmit只留在 ioctl 边界和最终 copy-back 边界- queue 只维护“这个 submit 还剩什么能调度”
- scheduler 独占 in-flight dispatch ownership
- driver / IRQ 只发布 per-core 原始完成状态
3. 各层现在分别负责什么
3.1 card1:阻塞 ioctl 入口
card1 现在只做三件事:
- 从用户态拷贝
RknpuSubmit和RknpuTask[] - 构造
RknpuQueuedSubmit并调用enqueue_submit(...) - 等待完成,取回
CompletedSubmit,再统一拷回用户态
它不再自己步进调度,也不再负责保存任何调度期内部状态。它只保留阻塞设备调用入口该有的职责。
3.2 NpuScheduler:真正的调度器
StarryOS 里的 NpuScheduler 是当前链路的控制中心。它手里有四类核心状态:
queue: RknpuTaskQueuewaiters: BTreeMap<RknpuQueueTaskId, Arc<NpuSubmitWaiter>>inflight: [Option<InflightDispatch>; NPU_MAX_CORES]kick: Event
分工很明确:
queue管 submit 级进度waiters管阻塞线程的睡眠和唤醒inflight管当前每个硬件 core 在跑哪一个 dispatchkick只负责把 worker 从睡眠态唤醒
也就是说,waiter 是 per-submit 的,kick 是全局的;二者分别解决“谁该睡”和“worker 什么时候该起来干活”两个完全不同的问题。
3.3 drivers/rknpu:单次硬件下发原语
驱动层现在退回到最小硬件编程层。它保留的核心原语就是:
submit_ioctrl_step(...)harvest_completed_dispatches()
其中:
submit_ioctrl_step(...)只负责把一个 task 发给一个 coreharvest_completed_dispatches()只负责把 IRQ top-half 已经发布好的 raw completion 收回来
驱动不再负责维护完整 submit 生命周期,也不再保存 queue 语义的绑定关系。
3.4 IRQ top-half:只发布 raw per-core completion
IRQ handler 现在只做最小动作:
- 读取硬件 IRQ 状态
- fuzz status
- 清硬件中断
- 把结果按 core 写入共享原子
它不直接继续调度,也不持有 queue 语义的数据结构。这样 top-half 足够短,行为也足够稳定。
4. 内部数据模型怎么收口
这版重构的核心不是“加了多少新类型”,而是把每个类型的边界收窄了。
4.1 RknpuSubmit 只留在边界
RknpuSubmit 现在只用于两处:
- ioctl 入口时承接用户态 header
- submit 终态时重新组装 copy-back 给用户态
调度期间不再把它当成一个全程可变的内部状态容器到处传、到处改。
4.2 SubmitMeta 是内部不可变输入视图
调度期真正使用的是 SubmitMeta。它只保留调度所需的固定字段:
flagsprioritycore_masktask_dma_baselane_rangestask_total
lane_ranges 在入队时就做一次归一化:
- 如果
subcore_task[]全空,就默认变成slot0 = [0, task_total) - 否则只按已有非空 lane 解释
这样后面的 queue / scheduler 不需要再在运行期反复猜 lane layout。
4.3 CompletedSubmit 是 terminal 返回模型
调度器在 terminal 时返回的不是整个 queue entry,而是一个更明确的结果模型:
submit: RknpuSubmittasks: Vec<RknpuTask>last_error: Option<RknpuError>
这个边界很重要,因为 card1 真正需要的只有这三样,不需要知道 queue 内部状态机细节。
4.4 InflightDispatch 是唯一的 in-flight owner
每个正在硬件上飞的 dispatch 现在只在 scheduler 的 inflight[core] 里有一份记录,里面保存:
queue_task_idcore_slotsubcore_slottask_indextask_ptrexpected_irq_mask
这份记录回答的就是一个问题:
“这个 core 当前跑的是哪个 submit 的哪个 task;如果 completion 回来,我该把结果记到哪里。”
queue 不再保存 per-core 反向绑定,driver 也不再保存 queue-facing 绑定。
4.5 CoreCompletion 是 driver 向 scheduler 提交的最小完成记录
driver harvest 之后只返回:
core_slotobserved_irq_status
scheduler 拿到它以后,再结合 InflightDispatch.expected_irq_mask 计算:
last_task_int_statustask_error
然后推进 queue 状态机。这一步把“硬件观测”与“队列语义”干净地分开了。
5. queue 是怎么维护游标和分发任务的
这部分是当前调度模型的核心。
5.1 queue 维护的是 submit 级进度,不是 per-core 绑定
RknpuQueueTask 里真正和调度推进相关的字段只有这些:
metataskssubcore_cursorssubcore_running_maskcompleted_task_countinflight_core_masklast_errorready_queued
语义分别是:
subcore_cursors:每个逻辑 lane 已经推进到该 lane 的第几个 tasksubcore_running_mask:某个 lane 当前是否已经有 task 在飞completed_task_count:这次 submit 已经完成了多少 taskinflight_core_mask:当前有哪些物理 core 正在执行这个 submitready_queued:这个 submit 当前是否已经挂在 ready 队列里,避免重复入队
5.2 reserve_next_dispatch() 只产出最小 reservation token
queue 不再给 scheduler 一整份“大计划”,而是一次只给一个最小 reservation:
queue_task_idsubcore_slottask_index
这意味着 queue 只负责说“下一个可以发的是谁”,不负责持有这个 dispatch 之后在 driver 侧的绑定信息。
5.3 游标推进规则
worker 调度时,queue 会按下面的规则挑任务:
- 先按 priority 从 ready 队列里挑 submit
- 再在这个 submit 内部按
subcore_slot扫描可运行 lane - 跳过已经在飞的 lane
- 用
subcore_cursors[slot]算出当前 lane 的下一个task_index - 成功 reservation 后,设置:
subcore_running_maskinflight_core_mask
completion 回来以后,再清掉对应 bit,并把该 lane 的 cursor 加一。
5.4 为什么同一个 submit 能同时占多个 core
因为 subcore_running_mask 限制的是“同一个 lane 不能并发重复下发”,不是“同一个 submit 只能占一个 core”。
所以只要:
- 这个 submit 还有别的 lane 可跑
- 目标 core 在
core_mask允许范围内 - 当前有空闲 core
那么同一个 submit 完全可以在一轮里占多个 core。
5.5 为什么 faulted submit 还要等 inflight core 排空
Faulted 不等于立即 terminal。
当前实现里,一个 submit 即便已经 faulted,只要 inflight_core_mask != 0,它还不能算 terminal。因为还有别的 core 上的 in-flight task 没收干净,waiter 这时不能提前醒。
所以 terminal 的判定是:
Completed- 或者
Faulted && inflight_core_mask == 0
6. 一次完整的 Submit 现在怎么走
第 1 步:用户态发起 ioctl
用户态传入 RknpuSubmit 和 RknpuTask[]。card1 把它们拷进内核 shadow。
第 2 步:构造 RknpuQueuedSubmit
card1 把原始 submit 拆成两部分:
- 边界专用的
RknpuSubmit - 调度专用的
SubmitMeta + Vec<RknpuTask>
然后包装成 RknpuQueuedSubmit 入队。
第 3 步:提交线程阻塞
enqueue_submit(...) 为这个 submit 建立自己的 NpuSubmitWaiter。随后提交线程执行 wait_for_submit(...),睡到 waiter 的 WaitQueue 上。
第 4 步:worker 被 kick 唤醒
新 submit 入队后,scheduler 调一次 kick.notify_relaxed(1)。worker 如果在睡眠,就会被唤醒开始工作。
这里的 kick 不是“某个 submit 的完成事件”,它只是一个全局“有活了,起来看队列”的唤醒信号。
第 5 步:worker 给空闲 core 分发任务
worker 会循环做两件事:
harvest_completed_cores()dispatch_idle_cores()
在 dispatch 路径里,它会:
- 找一个当前没有 inflight 的 core
- 让 queue 给出一个 reservation token
- 从 queue task 里取出对应 task,组装
InflightDispatch - 先写入
state.inflight[core] - 如果这是本轮第一次给这个 submit 发任务,就做一次
confirm_write_all() - 调用 driver 的
submit_ioctrl_step(...)
如果 driver dispatch 失败,就回滚 state.inflight[core] 和 queue reservation。
第 6 步:IRQ 到来,只发布原始完成状态
哪个 core 先完成,就哪个 core 的 top-half 先把 observed_irq_status 发布出来。此时不会直接继续调度。
第 7 步:worker harvest completion
worker 下次循环里会:
- 从 driver 拿到
CoreCompletion - 通过
state.inflight[core]找到对应InflightDispatch - 计算:
last_task_int_status = observed_irq_status & expected_irq_masktask_error
- 回写
task.int_status - 调用 queue 的
complete_dispatch(...)推进 submit 状态
如果 submit 已经 terminal,就把 task_id 记到 terminal 列表里。
第 8 步:terminal path 唤醒 waiter
terminal path 里,scheduler 会:
- 先做一次
prepare_read_all() - 然后唤醒该 submit 对应的 waiter
提交线程被唤醒后,再从 scheduler 取回 CompletedSubmit,并把最终的 task 数组和 submit header 一起拷回用户态。
7. 现在比旧模型少了什么
少掉的其实就是这次刻意拿掉的那些冗余状态。
7.1 不再有 submit 信息的多份影子副本
现在不会再在内部反复保存这些重复字段:
task_dma_addr和submit.task_base_addr的双存submit.task_obj_addr的内部影子submit.task_counter/submit.hw_elapse_time的调度期原地写回版本- queue 上额外存一份
priority
这些都被收回到更单一的边界里了。
7.2 不再有 queue 和 driver 的双重反向绑定
以前 queue 和 driver 都想回答“这个 core 当前到底在跑谁”。现在只有 scheduler 的 InflightDispatch 回答这个问题。
7.3 不再有只负责搬字段的 helper
像旧的 submit view 刷新、ready bit 翻转、active core 反查这类 helper,现在都不需要了。保留下来的 helper 都是状态机规则本身的一部分。
8. 当前实现里还需要注意的点
8.1 worker 还不是 IRQ 直接唤醒
当前 worker 在有 inflight core 时,还是通过轻量 yield_now() 轮询 harvest,而不是让 IRQ 直接把 worker 唤醒。
这不影响语义正确性,但如果以后继续优化内核态延迟,这里还有继续收紧的空间。
8.2 confirm_write_all() / prepare_read_all() 还是全局同步
现在还是按 GEM 池全局同步,不是按单 submit 精细同步。这版先保证路径和 ownership 干净,性能细化可以后面再做。
8.3 当前切换边界仍然是 task 完成后的 IRQ 边界
这版已经是多 submit、per-core streaming dispatch,但它仍然不是“任意时刻抢占正在执行的 NPU 指令流”。真正稳定的切换点还是 task 完成后的 IRQ 边界。
9. 队列相关结构体作用
这一节单独列一下和 queue / scheduler 直接相关的结构体,后面查代码时可以快速对照。
9.1 SubmitMeta
作用:submit 的内部不可变调度视图。
它只保留调度期真正要用的元数据:flag、priority、core_mask、DMA base、lane_ranges、task_total。它的意义是把 RknpuSubmit 从“内部运行时状态对象”降回“边界协议头”。
9.2 RknpuQueuedSubmit
作用:从 ioctl 边界进入 queue 时的输入容器。
它持有:
meta- reply-only 的 submit 字段
- shadow
tasks
它只活在“刚入队”这道边界上,目的就是把边界输入整理成 queue 可以直接接管的形式。
9.3 RknpuQueueTask
作用:一个已经入队、正在被调度器管理的 submit 实体。
它维护 submit 的生命周期状态、lane cursor、running mask、完成计数、错误状态,以及最终把终态重新组装回 RknpuSubmit 所需的 reply 信息。
9.4 RknpuTaskQueue
作用:scheduler 内部的 submit 容器和 ready 选择器。
它维护:
- 全部 queue task 总表
- 按 priority 分桶的 ready 队列
- 下一个 queue task id
它只做 submit 选择和 reservation,不做 per-core in-flight ownership。
9.5 RknpuDispatchReservation
作用:queue 交给 scheduler 的最小“可发任务 token”。
它只说明:
- 哪个 submit
- 哪个 lane
- 哪个 task_index
不带 driver 绑定,不带 task 指针,不带 IRQ 期望值。
9.6 InflightDispatch
作用:scheduler 独占的 per-core in-flight 记录。
它把 reservation 扩成真正能完成一次硬件 dispatch 和一次 completion 匹配所需的最小信息,包括 task 指针和 expected IRQ mask。
9.7 CoreCompletion
作用:driver 向 scheduler 返回的最小 raw completion。
它只表达“哪个 core 观察到了什么 IRQ 状态”,不掺杂 queue 语义。
9.8 CompletedSubmit
作用:terminal submit 返回给 card1 的结果模型。
它把 scheduler 内部状态机收敛成用户态真正需要的三样结果:
- 最终
submit - 最终
tasks - 最终
last_error
9.9 NpuSubmitWaiter
作用:一个 submit 对应一个阻塞原语。
原始 ioctl 线程就睡在这里,直到 terminal path 把它唤醒。它解决的是“这个 submit 的提交线程什么时候返回”。
9.10 kick: Event
作用:全局 worker 唤醒器。
它不对应某个 submit,也不携带完成结果。它只负责在“有新活可做”时把 worker 从睡眠态叫起来。
10. 用一句话收尾
这版实现真正做成的事情其实很具体:把 Submit 从“调用线程自己 loop 推完整次 submit 的独占路径”,改成了“对外阻塞、对内由 queue + worker 按 core streaming dispatch 推进”的模型。queue 只管 submit 进度,scheduler 独占 in-flight ownership,driver 和 IRQ 只保留原始硬件完成边界,最终结果再由原始提交线程统一回填用户态。
RKNN 用户库手册
概述
librknnrt.so 是 Rockchip 提供的闭源 NPU 运行时库,负责将神经网络模型编译为硬件命令流并提交给内核驱动执行。它是用户态与 NPU 硬件之间的桥梁。
架构层次
┌─────────────────────────────────────────────────┐
│ 用户应用程序 │
├─────────────────────────────────────────────────┤
│ rknn_api.h │ rknn_matmul_api.h │ ← 闭源库公开头文件
├──────────────────────┼──────────────────────────┤
│ librknnrt.so(闭源) │
│ ┌──────────┐ ┌──────────┐ ┌──────────────────┐ │
│ │模型解析器 │ │图优化/编译│ │命令流生成 + Task │ │
│ └──────────┘ └──────────┘ └──────────────────┘ │
├─────────────────────────────────────────────────┤
│ DRM ioctl (DRM_IOCTL_RKNPU_*) │ ← 开源 ABI
├─────────────────────────────────────────────────┤
│ rknpu 内核驱动(开源 GPL) │
│ 任务调度 │ GEM 内存 │ 中断处理 │ PC 寄存器写入 │
├─────────────────────────────────────────────────┤
│ NPU 硬件(CNA / CORE / DPU / PPU) │
└─────────────────────────────────────────────────┘
两条 NPU 使用路径
| 路径 | 依赖 | 操作方式 | 代表项目 |
|---|---|---|---|
| 闭源 API 路径 | librknnrt.so | rknn_init → rknn_run → rknn_outputs_get | yolov8 demo |
| 裸 ioctl 路径 | 仅 libdrm + 内核驱动 | 用户自行构造命令流 + DRM_IOCTL_RKNPU_SUBMIT | npu_benchmark / npu_llama |
闭源库封装了命令流生成、内存规划、多核调度等全部复杂逻辑;裸 ioctl 路径则要求用户自己实现这些。
闭源库提供的三套 API
| 头文件 | 功能 | 说明 |
|---|---|---|
rknn_api.h | 模型推理 | 加载 .rknn 模型 → 设置输入 → 推理 → 获取输出 |
rknn_matmul_api.h | 矩阵乘法加速 | 独立于模型推理的通用 matmul 接口 |
rknn_custom_op.h | 自定义算子 | 注册用户实现的 CPU/GPU 算子回调 |
闭源库二进制
仓库中 test/starrynpu/demo/yolov8/3rdparty/ 包含实际二进制:
| 文件 | 说明 |
|---|---|
rknpu2/Linux/aarch64/librknnrt.so | RKNPU2 闭源运行时(当前版本) |
rknpu1/Linux/aarch64/librknn_api.so | RKNPU1 旧版 API 库 |
rknpu2/include/rknn_api.h | 推理 API 头文件(805 行) |
rknpu2/include/rknn_matmul_api.h | Matmul API 头文件(544 行) |
rknpu2/include/rknn_custom_op.h | 自定义算子 API 头文件(145 行) |
文档结构
- 推理 API 参考 —
rknn_api.h全部函数签名与逆向还原 - 矩阵乘法 API —
rknn_matmul_api.h与 Native Layout 规范 - 自定义算子 API —
rknn_custom_op.h回调机制 - 模型推理全链条 — 从加载到运行到结束的完整逻辑链条
- 内存管理与零拷贝 — 闭源库的内存分配策略
- 闭源库内部机制 — 命令流生成、Task 构造、多核切分
推理 API 参考(rknn_api.h)
来源:
test/starrynpu/demo/yolov8/3rdparty/rknpu2/include/rknn_api.h以下资料均来着StarryOS或社区收集。大多数暂未经过验证!。
一、类型定义
1.1 上下文句柄
#ifdef __arm__
typedef uint32_t rknn_context;
#else
typedef uint64_t rknn_context;
所有 API 围绕 rknn_context 句柄操作,内部指向闭源库维护的不透明状态。
1.2 错误码
| 常量 | 值 | 说明 |
|---|---|---|
RKNN_SUCC | 0 | 成功 |
RKNN_ERR_FAIL | -1 | 通用失败 |
RKNN_ERR_TIMEOUT | -2 | 执行超时 |
RKNN_ERR_DEVICE_UNAVAILABLE | -3 | 设备不可用 |
RKNN_ERR_MALLOC_FAIL | -4 | 内存分配失败 |
RKNN_ERR_PARAM_INVALID | -5 | 参数无效 |
RKNN_ERR_MODEL_INVALID | -6 | 模型无效 |
RKNN_ERR_CTX_INVALID | -7 | 上下文无效 |
RKNN_ERR_INPUT_INVALID | -8 | 输入无效 |
RKNN_ERR_OUTPUT_INVALID | -9 | 输出无效 |
RKNN_ERR_DEVICE_UNMATCH | -10 | 设备不匹配(需更新 SDK/驱动) |
RKNN_ERR_INCOMPATILE_PRE_COMPILE_MODEL | -11 | 预编译模型不兼容 |
RKNN_ERR_INCOMPATILE_OPTIMIZATION_LEVEL_VERSION | -12 | 优化级别版本不兼容 |
RKNN_ERR_TARGET_PLATFORM_UNMATCH | -13 | 目标平台不匹配 |
1.3 张量类型
typedef enum _rknn_tensor_type {
RKNN_TENSOR_FLOAT32 = 0,
RKNN_TENSOR_FLOAT16, // 1
RKNN_TENSOR_INT8, // 2
RKNN_TENSOR_UINT8, // 3
RKNN_TENSOR_INT16, // 4
RKNN_TENSOR_UINT16, // 5
RKNN_TENSOR_INT32, // 6
RKNN_TENSOR_UINT32, // 7
RKNN_TENSOR_INT64, // 8
RKNN_TENSOR_BOOL, // 9
RKNN_TENSOR_INT4, // 10
RKNN_TENSOR_BFLOAT16, // 11
} rknn_tensor_type;
1.4 量化类型
typedef enum _rknn_tensor_qnt_type {
RKNN_TENSOR_QNT_NONE = 0, // 无量化
RKNN_TENSOR_QNT_DFP, // 动态定点(fractional length)
RKNN_TENSOR_QNT_AFFINE_ASYMMETRIC, // 非对称仿射(zero_point + scale)
} rknn_tensor_qnt_type;
1.5 数据格式
typedef enum _rknn_tensor_format {
RKNN_TENSOR_NCHW = 0,
RKNN_TENSOR_NHWC,
RKNN_TENSOR_NC1HWC2, // NPU 原生格式
RKNN_TENSOR_UNDEFINED,
} rknn_tensor_format;
1.6 核心掩码
typedef enum _rknn_core_mask {
RKNN_NPU_CORE_AUTO = 0, // 自动选择
RKNN_NPU_CORE_0 = 1, // 核心 0
RKNN_NPU_CORE_1 = 2, // 核心 1
RKNN_NPU_CORE_2 = 4, // 核心 2
RKNN_NPU_CORE_0_1 = 3, // 核心 0+1 联合
RKNN_NPU_CORE_0_1_2 = 7, // 三核联合
RKNN_NPU_CORE_ALL = 0xffff, // 平台自动选择多核
} rknn_core_mask;
1.7 初始化标志
| 标志 | 值 | 说明 | 逆向推断的内部行为 |
|---|---|---|---|
RKNN_FLAG_PRIOR_HIGH | 0x0 | 高优先级(默认) | 设置 nice -19 |
RKNN_FLAG_PRIOR_MEDIUM | 0x1 | 中优先级 | — |
RKNN_FLAG_PRIOR_LOW | 0x2 | 低优先级 | — |
RKNN_FLAG_ASYNC_MASK | 0x4 | 异步模式 | rknn_outputs_get 返回上一帧结果 |
RKNN_FLAG_COLLECT_PERF_MASK | 0x8 | 性能采集 | 启用逐层计时,降低帧率 |
RKNN_FLAG_MEM_ALLOC_OUTSIDE | 0x10 | 外部内存分配 | 用户负责分配 weight/internal/IO 内存 |
RKNN_FLAG_SHARE_WEIGHT_MEM | 0x20 | 权重共享 | 多上下文共享同一权重内存 |
RKNN_FLAG_FENCE_IN_OUTSIDE | 0x40 | 外部输入 fence | 传入 DMA fence fd |
RKNN_FLAG_FENCE_OUT_OUTSIDE | 0x80 | 外部输出 fence | 获取 DMA fence fd |
RKNN_FLAG_COLLECT_MODEL_INFO_ONLY | 0x100 | 仅采集模型信息 | 不实际加载,仅查询 weight/internal 大小 |
RKNN_FLAG_INTERNAL_ALLOC_OUTSIDE | 0x200 | 外部分配内部内存 | — |
RKNN_FLAG_EXECUTE_FALLBACK_PRIOR_DEVICE_GPU | 0x400 | GPU 回退 | NPU 不支持的算子回退 GPU(OpenCL) |
RKNN_FLAG_ENABLE_SRAM | 0x800 | 启用 SRAM | 尝试在 SRAM 分配缓冲 |
RKNN_FLAG_SHARE_SRAM | 0x1000 | 共享 SRAM | 多上下文共享 SRAM |
RKNN_FLAG_DISABLE_PROC_HIGH_PRIORITY | 0x2000 | 禁用高优先级 | 不设置 nice -19 |
RKNN_FLAG_DISABLE_FLUSH_INPUT_MEM_CACHE | 0x4000 | 禁用输入 cache flush | 用户自行保证 cache 一致性 |
RKNN_FLAG_DISABLE_FLUSH_OUTPUT_MEM_CACHE | 0x8000 | 禁用输出 cache flush | 输出由 GPU/RGA 消费时使用 |
RKNN_FLAG_MODEL_BUFFER_ZERO_COPY | 0x10000 | 模型缓冲零拷贝 | 模型数据由 NPU 直接访问 |
二、核心结构体
2.1 张量属性 rknn_tensor_attr
typedef struct _rknn_tensor_attr {
uint32_t index; // 输入/输出索引
uint32_t n_dims; // 维度数
uint32_t dims[RKNN_MAX_DIMS]; // 维度数组(最多 16 维)
char name[RKNN_MAX_NAME_LEN]; // 张量名(最长 256)
uint32_t n_elems; // 元素总数
uint32_t size; // 字节大小
rknn_tensor_format fmt; // 数据格式(NCHW/NHWC/NC1HWC2)
rknn_tensor_type type; // 数据类型
rknn_tensor_qnt_type qnt_type; // 量化类型
int8_t fl; // DFP 小数位长度
int32_t zp; // 仿射量化零点
float scale; // 仿射量化缩放因子
uint32_t w_stride; // 宽度方向步长(只读)
uint32_t size_with_stride; // 含步长的字节大小
uint8_t pass_through; // 直通模式标志
uint32_t h_stride; // 高度方向步长(只写)
} rknn_tensor_attr;
2.2 张量内存 rknn_tensor_mem
typedef struct _rknn_tensor_memory {
void* virt_addr; // 虚拟地址
uint64_t phys_addr; // 物理地址
int32_t fd; // DMA buffer fd
int32_t offset; // 内存偏移
uint32_t size; // 缓冲大小
uint32_t flags; // 标志
void* priv_data; // 私有数据(闭源库内部使用)
} rknn_tensor_mem;
逆向推断:priv_data 内部指向闭源库维护的 rknpu_mem_create 返回的 obj_addr,用于后续 mem_destroy 和 mem_sync 操作。
2.3 查询命令 rknn_query_cmd
| 命令 | 值 | 返回结构体 | 说明 |
|---|---|---|---|
RKNN_QUERY_IN_OUT_NUM | 0 | rknn_input_output_num | 输入/输出数量 |
RKNN_QUERY_INPUT_ATTR | 1 | rknn_tensor_attr | 输入张量属性 |
RKNN_QUERY_OUTPUT_ATTR | 2 | rknn_tensor_attr | 输出张量属性 |
RKNN_QUERY_PERF_DETAIL | 3 | rknn_perf_detail | 逐层性能(需 PERF_MASK) |
RKNN_QUERY_PERF_RUN | 4 | rknn_perf_run | 推理总耗时 |
RKNN_QUERY_SDK_VERSION | 5 | rknn_sdk_version | SDK/驱动版本 |
RKNN_QUERY_MEM_SIZE | 6 | rknn_mem_size | 权重/内部内存大小 |
RKNN_QUERY_CUSTOM_STRING | 7 | rknn_custom_string | 自定义字符串 |
RKNN_QUERY_NATIVE_INPUT_ATTR | 8 | rknn_tensor_attr | 原生输入属性(NC1HWC2) |
RKNN_QUERY_NATIVE_OUTPUT_ATTR | 9 | rknn_tensor_attr | 原生输出属性 |
RKNN_QUERY_DEVICE_MEM_INFO | 12 | — | 设备内存信息 |
RKNN_QUERY_INPUT_DYNAMIC_RANGE | 13 | rknn_input_range | 动态 shape 范围 |
RKNN_QUERY_CURRENT_INPUT_ATTR | 14 | rknn_tensor_attr | 当前输入 shape(动态模型) |
RKNN_QUERY_CURRENT_OUTPUT_ATTR | 15 | rknn_tensor_attr | 当前输出 shape(动态模型) |
三、函数签名与逆向还原
3.1 生命周期管理
rknn_init
int rknn_init(rknn_context* context, void* model, uint32_t size, uint32_t flag, rknn_init_extend* extend);
| 参数 | 说明 |
|---|---|
context | [out] 上下文句柄指针 |
model | size > 0 时为模型数据指针;size = 0 时为模型文件路径 |
size | 模型数据大小(0 表示从文件加载) |
flag | 初始化标志组合(见 1.7) |
extend | 扩展信息(可选,含 real_model_offset、model_buffer_fd 等) |
逆向还原的内部流程:
rknn_init()
├── 1. 打开 /dev/dri/card* 或 /dev/rknpu(获取 fd)
├── 2. ioctl(ACTION, RKNPU_GET_HW_VERSION) → 检查硬件版本
├── 3. 解析 .rknn 模型文件头
│ ├── 提取网络拓扑(层数、连接关系)
│ ├── 提取权重数据
│ └── 提取预编译命令流(如果是 pre-compile 模型)
├── 4. ioctl(MEM_CREATE) × N → 分配权重/内部/IO 内存
│ ├── 权重内存(RKNPU_MEM_KERNEL_MAPPING)
│ ├── 内部中间缓冲
│ └── 命令流缓冲(regcmd)
├── 5. ioctl(MEM_MAP) + mmap() → 映射到用户空间
├── 6. 将权重数据拷贝到 DMA 内存(转换为 native layout)
├── 7. 编译模型 → 生成寄存器命令流
│ ├── 为每层生成 NPUOP 指令序列
│ ├── 计算 CBUF bank 分配
│ └── 生成 Task 数组
├── 8. 如果 flag & RKNN_FLAG_PRIOR_HIGH → ioctl(ACTION, RKNPU_SET_PROC_NICE)
└── 9. 返回 context 句柄
rknn_destroy
int rknn_destroy(rknn_context context);
逆向还原:
rknn_destroy()
├── 1. 释放所有 Task 数组内存
├── 2. munmap() + ioctl(MEM_DESTROY) × N → 释放所有 DMA 内存
├── 3. close(drm_fd)
└── 4. 释放上下文结构体
rknn_dup_context
int rknn_dup_context(rknn_context* context_in, rknn_context* context_out);
复制上下文,新上下文与原上下文共享权重内存(RKNN_FLAG_SHARE_WEIGHT_MEM 语义)。
3.2 推理流程
rknn_inputs_set
int rknn_inputs_set(rknn_context context, uint32_t n_inputs, rknn_input inputs[]);
逆向还原:
rknn_inputs_set()
├── 1. 遍历 inputs[]
│ ├── 如果 pass_through == TRUE → 直接拷贝到输入 DMA 内存
│ └── 如果 pass_through == FALSE →
│ ├── 格式转换(NHWC → NCHW 或 NC1HWC2)
│ ├── 类型转换(FP32 → INT8/FP16,应用 scale/zp)
│ └── 拷贝到输入 DMA 内存
└── 2. ioctl(MEM_SYNC, SYNC_TO_DEVICE) → flush cache
rknn_run
int rknn_run(rknn_context context, rknn_run_extend* extend);
| 参数 | 说明 |
|---|---|
extend->frame_id | [out] 当前帧 ID |
extend->non_block | 0=阻塞,1=非阻塞 |
extend->timeout_ms | 阻塞模式超时(毫秒) |
extend->fence_fd | 外部 fence fd |
逆向还原(核心路径):
rknn_run()
├── 1. 构造 rknpu_submit 结构体
│ ├── flags = RKNPU_JOB_PC | RKNPU_JOB_BLOCK(或 NONBLOCK)| RKNPU_JOB_PINGPONG
│ ├── task_obj_addr = tasks DMA 对象地址
│ ├── core_mask = 根据 rknn_set_core_mask() 设置
│ ├── subcore_task[] = 根据多核切分策略填充
│ └── timeout = extend->timeout_ms 或默认值
├── 2. ioctl(DRM_IOCTL_RKNPU_SUBMIT, &submit)
│ └── 内核驱动:
│ ├── 分配 job → 调度到核心
│ ├── 写 PC 寄存器(base_addr, amount, task_control, op_enable)
│ ├── 等待中断
│ └── 写回 task[].int_status
└── 3. 如果阻塞模式 → 等待 ioctl 返回
如果非阻塞 → 立即返回,后续 rknn_wait() 或 rknn_outputs_get() 等待
rknn_wait
int rknn_wait(rknn_context context, rknn_run_extend* extend);
等待非阻塞推理完成。内部轮询或等待 fence 信号。
rknn_outputs_get
int rknn_outputs_get(rknn_context context, uint32_t n_outputs, rknn_output outputs[], rknn_output_extend* extend);
逆向还原:
rknn_outputs_get()
├── 1. 如果异步模式 → 返回上一帧结果(不等待当前帧)
├── 2. ioctl(MEM_SYNC, SYNC_FROM_DEVICE) → invalidate output cache
├── 3. 遍历 outputs[]
│ ├── 如果 want_float == TRUE →
│ │ ├── 反量化(INT8 → FP32,应用 scale/zp)
│ │ └── 格式转换(NC1HWC2 → NCHW/NHWC)
│ ├── 如果 is_prealloc == TRUE → 拷贝到用户提供的 buf
│ └── 如果 is_prealloc == FALSE → 分配 buf 并拷贝
└── 4. extend->frame_id = 当前帧 ID
rknn_outputs_release
int rknn_outputs_release(rknn_context context, uint32_t n_ouputs, rknn_output outputs[]);
释放 rknn_outputs_get 中 is_prealloc == FALSE 时分配的 buf。
3.3 查询接口
rknn_query
int rknn_query(rknn_context context, rknn_query_cmd cmd, void* info, uint32_t size);
通用查询接口。info 指向对应结构体,size 为结构体大小。
关键查询结构体:
typedef struct _rknn_input_output_num {
uint32_t n_input;
uint32_t n_output;
} rknn_input_output_num;
typedef struct _rknn_perf_detail {
char* perf_data; // 性能数据字符串(闭源库内部分配)
uint64_t data_len;
} rknn_perf_detail;
typedef struct _rknn_perf_run {
int64_t run_duration; // 推理耗时(微秒)
} rknn_perf_run;
typedef struct _rknn_sdk_version {
char api_version[256];
char drv_version[256];
} rknn_sdk_version;
typedef struct _rknn_mem_size {
uint32_t total_weight_size;
uint32_t total_internal_size;
uint64_t total_dma_allocated_size;
uint32_t total_sram_size;
uint32_t free_sram_size;
uint32_t reserved[10];
} rknn_mem_size;
3.4 多核控制
rknn_set_core_mask
int rknn_set_core_mask(rknn_context context, rknn_core_mask core_mask);
逆向推断:设置后续 rknn_run 提交时 rknpu_submit.core_mask 的值。对于联合核心模式(CORE_0_1、CORE_0_1_2),闭源库内部会将 Task 数组切分到 subcore_task[] 中。
rknn_set_batch_core_num
int rknn_set_batch_core_num(rknn_context context, int core_num);
设置批量推理时使用的核心数。
3.5 动态 Shape
rknn_set_input_shapes
int rknn_set_input_shapes(rknn_context ctx, uint32_t n_inputs, rknn_tensor_attr attr[]);
设置所有输入张量的 shape。仅对动态 shape 模型有效。调用后闭源库内部会重新编译命令流。
rknn_set_input_shape(已废弃)
int rknn_set_input_shape(rknn_context ctx, rknn_tensor_attr* attr);
3.6 扩展结构体
rknn_init_extend
typedef struct _rknn_init_extend {
rknn_context ctx;
int32_t real_model_offset; // 模型文件内偏移(零拷贝模式)
uint32_t real_model_size; // 模型实际大小
int32_t model_buffer_fd; // 模型缓冲 fd
uint32_t model_buffer_flags; // 模型缓冲标志
uint8_t reserved[112];
} rknn_init_extend;
rknn_run_extend
typedef struct _rknn_run_extend {
uint64_t frame_id; // [out] 帧 ID
int32_t non_block; // 0=阻塞,1=非阻塞
int32_t timeout_ms; // 超时(毫秒)
int32_t fence_fd; // 外部 fence fd
} rknn_run_extend;
rknn_output_extend
typedef struct _rknn_output_extend {
uint64_t frame_id; // [out] 输出对应的帧 ID
} rknn_output_extend;
矩阵乘法 API(rknn_matmul_api.h)
来源:
test/starrynpu/demo/yolov8/3rdparty/rknpu2/include/rknn_matmul_api.h(544 行)
独立于模型推理的通用矩阵乘法加速接口。公式:C = A × B。
一、支持的计算类型
typedef enum _rknn_matmul_type {
RKNN_FLOAT16_MM_FLOAT16_TO_FLOAT32 = 1, // FP16 × FP16 → FP32
RKNN_INT8_MM_INT8_TO_INT32 = 2, // INT8 × INT8 → INT32
RKNN_INT8_MM_INT8_TO_INT8 = 3, // INT8 × INT8 → INT8
RKNN_FLOAT16_MM_FLOAT16_TO_FLOAT16 = 4, // FP16 × FP16 → FP16
RKNN_FLOAT16_MM_INT8_TO_FLOAT32 = 5, // FP16 × INT8 → FP32
RKNN_FLOAT16_MM_INT8_TO_FLOAT16 = 6, // FP16 × INT8 → FP16
RKNN_FLOAT16_MM_INT4_TO_FLOAT32 = 7, // FP16 × INT4 → FP32
RKNN_FLOAT16_MM_INT4_TO_FLOAT16 = 8, // FP16 × INT4 → FP16
RKNN_INT8_MM_INT8_TO_FLOAT32 = 9, // INT8 × INT8 → FP32
RKNN_INT4_MM_INT4_TO_INT16 = 10, // INT4 × INT4 → INT16
RKNN_INT8_MM_INT4_TO_INT32 = 11, // INT8 × INT4 → INT32
RKNN_FLOAT16_MM_INT4_TO_BFLOAT16 = 12, // FP16 × INT4 → BF16
RKNN_INT8_MM_INT4_TO_FLOAT16 = 15, // INT8 × INT4 → FP16
} rknn_matmul_type;
二、对齐要求
RK3588 / RK3576
| 精度 | K 对齐 | N 对齐 | K 最大值 |
|---|---|---|---|
| INT4 | 32 字节 | 64 字节 | 10240 |
| INT8 | 32 字节 | 32 字节 | 10240 |
| FP16 | 32 字节 | 16 字节 | 10240 |
RK3566 / RK3568
| 精度 | K 对齐 | N 对齐 |
|---|---|---|
| INT8 | 32 字节 | 16 字节 |
| FP16 | 16 字节 | 8 字节 |
RK3562
| 精度 | K 对齐 | N 对齐 |
|---|---|---|
| INT8 | 32 字节 | 16 字节 |
| FP16 | 32 字节 | 8 字节 |
三、Native Layout 规范
硬件要求输入/输出数据按特定分块格式排列。使用 native layout 可避免闭源库内部的格式转换开销。
3.1 A 矩阵(M × K)
Normal layout:(M, K) — 行主序。
Native layout(RK3588/3576):
| 精度 | 布局 | 说明 |
|---|---|---|
| INT4 | (K/32, M, 32) | 每 32 个 K 元素为一组 |
| INT8 | (K/16, M, 16) | 每 16 个 K 元素为一组 |
| FP16 | (K/8, M, 8) | 每 8 个 K 元素为一组 |
示例(FP16):
[K1M1, K2M1, ..., K8M1,
K1M2, K2M2, ..., K8M2,
...
K(k-7)Mm, K(k-6)Mm, ..., KkMm]
3.2 B 矩阵(K × N)
Normal layout:(K, N) — 行主序。
Native layout(RK3588/3576):
| 精度 | 布局 | 说明 |
|---|---|---|
| INT4 | (N/64, K/32, 64, 32) | 64×32 分块 |
| INT8 | (N/32, K/32, 32, 32) | 32×32 分块 |
| FP16 | (N/16, K/32, 16, 32) | 16×32 分块 |
示例(INT8, RK3588):
[K1N1, K2N1, ..., K32N1,
K1N2, K2N2, ..., K32N2,
...
K1N32, K2N32, ..., K32N32, ← 第一个 32×32 块
K33N1, K34N1, ..., K64N1,
...
K(k-31)N32, ..., KkN32, ← 第二个 K 块
K1N33, K2N33, ..., K32N33, ← 第二个 N 块
...]
3.3 C 矩阵(M × N)
Normal layout:(M, N) — 行主序。
Native layout:
| 平台 | 精度 | 布局 |
|---|---|---|
| 通用 | 通用 | (N/4, M, 4) |
| RK3588 | INT4 | (N/8, M, 8) |
3.4 K 分段规则
当 K 超过硬件限制时,B 矩阵自动分段:
| 平台 | 分段阈值 | 分段数 |
|---|---|---|
| RK3588 | K > 8192 | T = ceil(K / 8192) |
| RK3576 | K > 4096 | T = ceil(K / 4096) |
分段后每段独立按 native layout 排列。推荐使用 rknn_B_normal_layout_to_native_layout() 进行自动转换。
四、函数签名
4.1 创建与销毁
rknn_matmul_create
int rknn_matmul_create(rknn_matmul_ctx* ctx, rknn_matmul_info* info, rknn_matmul_io_attr* io_attr);
| 参数 | 说明 |
|---|---|
ctx | [out] matmul 上下文句柄 |
info | [in] matmul 配置(M/K/N、类型、布局、量化) |
io_attr | [out] 输入/输出属性(含实际维度和大小) |
rknn_matmul_create_dynamic_shape
int rknn_matmul_create_dynamic_shape(rknn_matmul_ctx* ctx, rknn_matmul_info* info,
int shape_num, rknn_matmul_shape dynamic_shapes[], rknn_matmul_io_attr io_attrs[]);
创建支持动态 M/K/N 的 matmul 上下文。info.M/K/N 无效,以 dynamic_shapes[] 为准。
rknn_matmul_destroy
int rknn_matmul_destroy(rknn_matmul_ctx ctx);
4.2 IO 绑定
rknn_matmul_set_io_mem
int rknn_matmul_set_io_mem(rknn_matmul_ctx ctx, rknn_tensor_mem* mem, rknn_matmul_tensor_attr* attr);
绑定 A/B/C 矩阵的内存。attr 来自 rknn_matmul_create 返回的 io_attr。
4.3 执行
rknn_matmul_run
int rknn_matmul_run(rknn_matmul_ctx ctx);
阻塞执行矩阵乘法。
逆向推断的内部流程:
rknn_matmul_run()
├── 1. 根据 M/K/N 和精度生成命令流
│ ├── 填充 CNA 描述符(卷积参数映射为 matmul)
│ ├── 填充 CORE 描述符
│ └── 填充 DPU 描述符(输出转换)
├── 2. 构造 rknpu_task 数组
│ ├── enable_mask = 0xd(CNA + CORE + DPU)
│ ├── int_mask = 0x300(DPU 完成中断)
│ └── regcmd_addr = 命令流 DMA 地址
├── 3. 构造 rknpu_submit
│ ├── flags = RKNPU_JOB_PC | RKNPU_JOB_BLOCK | RKNPU_JOB_PINGPONG
│ └── core_mask = 根据 rknn_matmul_set_core_mask() 设置
└── 4. ioctl(DRM_IOCTL_RKNPU_SUBMIT)
4.4 核心控制
rknn_matmul_set_core_mask
int rknn_matmul_set_core_mask(rknn_matmul_ctx context, rknn_core_mask core_mask);
4.5 量化参数
rknn_matmul_set_quant_params
int rknn_matmul_set_quant_params(rknn_matmul_ctx context, rknn_quant_params* params);
设置量化参数。仅支持 INT8_MM_INT8_TO_INT8 和 INT8_MM_INT8_TO_INT32 类型。
rknn_matmul_get_quant_params
int rknn_matmul_get_quant_params(rknn_matmul_ctx ctx, rknn_quant_params* params, float* scale);
4.6 动态 Shape
rknn_matmul_set_dynamic_shape
int rknn_matmul_set_dynamic_shape(rknn_matmul_ctx ctx, rknn_matmul_shape* shape);
运行时切换 M/K/N(目前仅支持 M 动态)。
4.7 布局转换
rknn_B_normal_layout_to_native_layout
int rknn_B_normal_layout_to_native_layout(void* B_input, void* B_output, int K, int N, rknn_matmul_info* info);
将 B 矩阵从 normal layout 转换为 native layout。处理 K 分段和平台差异。
五、配置结构体
rknn_matmul_info
typedef struct rknn_matmul_info_t {
int32_t M;
int32_t K;
int32_t N;
rknn_matmul_type type; // 计算类型
int16_t B_layout; // 0=normal, 1=native
int16_t B_quant_type; // 0=per-layer, 1=per-channel, 2=per-group
int16_t AC_layout; // 0=normal, 1=native
int16_t AC_quant_type; // 仅支持 0
int32_t iommu_domain_id; // IOMMU 域 ID
int16_t group_size; // per-group 量化的组大小
int8_t reserved[34];
} rknn_matmul_info;
rknn_quant_params
typedef struct _rknn_quant_params {
char name[RKNN_MAX_NAME_LEN];
float* scale; // 缩放因子数组
int32_t scale_len;
int32_t* zp; // 零点数组
int32_t zp_len;
} rknn_quant_params;
六、与裸 ioctl demo 的对应关系
npu_benchmark 和 npu_llama 中的手工 matmul 实现,本质上是 rknn_matmul_run() 内部逻辑的开源复刻:
| 闭源 API | 裸 ioctl demo 对应 |
|---|---|
rknn_matmul_create() | gen_matmul_fp16() / gen_matmul_int8() 生成命令流 |
rknn_matmul_set_io_mem() | mem_allocate() + weight_fp16() / feature_data() 排列数据 |
rknn_matmul_run() | 填充 rknpu_task + rknpu_submit + ioctl(SUBMIT) |
rknn_matmul_destroy() | munmap() + mem_destroy() |
| native layout | weight_fp16() / weight_int8() / feature_data() 函数 |
自定义算子 API(rknn_custom_op.h)
来源:
test/starrynpu/demo/yolov8/3rdparty/rknpu2/include/rknn_custom_op.h(145 行)
当模型中包含 NPU 不支持的算子时,闭源库提供自定义算子机制,允许用户注册 CPU 或 GPU(OpenCL)回调函数来实现这些算子。
一、核心概念
模型推理流程中遇到不支持的算子:
NPU 执行 layer 0~5
→ 自定义算子回调执行 layer 6(CPU/GPU)
→ NPU 继续执行 layer 7~N
闭源库在推理过程中自动调度:NPU 可执行的层在 NPU 上运行,不支持的层调用用户注册的回调。
二、类型定义
2.1 执行后端
typedef enum _rknn_target_type {
RKNN_TARGET_TYPE_CPU = 1, // CPU 后端
RKNN_TARGET_TYPE_GPU = 2, // GPU 后端(OpenCL)
} rknn_target_type;
2.2 GPU 上下文
typedef struct _rknn_gpu_op_context {
void* cl_context; // OpenCL context
void* cl_command_queue; // OpenCL command queue
void* cl_kernel; // OpenCL kernel
} rknn_gpu_op_context;
2.3 算子上下文
typedef struct _rknn_custom_op_context {
rknn_target_type target; // 后端类型
rknn_custom_op_interal_context internal_ctx; // 闭源库内部上下文
rknn_gpu_op_context gpu_ctx; // GPU 上下文
void* priv_data; // 用户私有数据
} rknn_custom_op_context;
2.4 算子张量
typedef struct _rknn_custom_op_tensor {
rknn_tensor_attr attr; // 张量属性(维度、类型、量化参数)
rknn_tensor_mem mem; // 张量内存(虚拟地址、物理地址、fd)
} rknn_custom_op_tensor;
2.5 算子属性
typedef struct _rknn_custom_op_attr {
char name[RKNN_MAX_NAME_LEN]; // 属性名
rknn_tensor_type dtype; // 数据类型
uint32_t n_elems; // 元素数量
void* data; // 属性数据指针
} rknn_custom_op_attr;
三、算子注册结构体
typedef struct _rknn_custom_op {
uint32_t version; // 版本号
rknn_target_type target; // CPU 或 GPU
char op_type[RKNN_MAX_NAME_LEN]; // 算子类型名
// GPU(OpenCL)专用字段
char cl_kernel_name[RKNN_MAX_NAME_LEN]; // OpenCL kernel 名
char* cl_kernel_source; // kernel 源码或文件路径
uint64_t cl_source_size; // 源码大小(0=文件路径)
char cl_build_options[RKNN_MAX_NAME_LEN]; // 编译选项
// 回调函数
int (*init)(rknn_custom_op_context* op_ctx,
rknn_custom_op_tensor* inputs, uint32_t n_inputs,
rknn_custom_op_tensor* outputs, uint32_t n_outputs);
// [可选] 初始化回调
int (*prepare)(rknn_custom_op_context* op_ctx,
rknn_custom_op_tensor* inputs, uint32_t n_inputs,
rknn_custom_op_tensor* outputs, uint32_t n_outputs);
// [可选] 准备回调
int (*compute)(rknn_custom_op_context* op_ctx,
rknn_custom_op_tensor* inputs, uint32_t n_inputs,
rknn_custom_op_tensor* outputs, uint32_t n_outputs);
// [必须] 计算回调
int (*compute_native)(rknn_custom_op_context* op_ctx,
rknn_custom_op_tensor* inputs, uint32_t n_inputs,
rknn_custom_op_tensor* outputs, uint32_t n_outputs);
// [可选] 原生属性计算回调(当前不支持)
int (*destroy)(rknn_custom_op_context* op_ctx);
// [可选] 销毁回调
} rknn_custom_op;
特殊返回值:init 回调返回 RKNN_WARNING_SKIP_CUSTOM_OP_COMPUTE(-14)时,如果该算子类型被 RKNN 内部支持,则使用内部实现而非自定义回调。
四、函数签名
rknn_register_custom_ops
int rknn_register_custom_ops(rknn_context ctx, rknn_custom_op* op, uint32_t custom_op_num);
| 参数 | 说明 |
|---|---|
ctx | rknn 上下文(必须在 rknn_init 之后调用) |
op | 自定义算子数组 |
custom_op_num | 数组长度 |
使用步骤:
- 创建
rknn_custom_op结构体数组 - 填写
op_type、target、回调函数 - 在
rknn_init()之后调用rknn_register_custom_ops()
rknn_custom_op_get_op_attr
void rknn_custom_op_get_op_attr(rknn_custom_op_context* op_ctx,
const char* attr_name,
rknn_custom_op_attr* op_attr);
在回调函数内部调用,获取模型中定义的算子属性(如 kernel_size、stride 等)。
五、动态加载机制
闭源库支持通过 dlopen 加载自定义算子 .so:
typedef rknn_custom_op* (*get_custom_op_func)();
自定义算子 .so 需导出 get_custom_op_func 类型的函数,返回 rknn_custom_op 指针。需使用 RKNN_CUSTOM_OP_EXPORT(__attribute__((visibility("default"))))标记导出函数。
模型推理全链条分析
从加载 .rknn 模型到推理完成到资源释放的完整逻辑链条。
逆向来源:闭源库头文件
rknn_api.h、开源内核驱动rknpu/、裸 ioctl demonpu_benchmark/npu_llama、StarryOS Rust 驱动。
一、全链条总览
┌──────────────────────────────────────────────────────────────────┐
│ 阶段 1:初始化 │
│ rknn_init() │
│ ├── 打开设备 → 检查硬件版本 │
│ ├── 解析 .rknn 模型 │
│ ├── 分配 DMA 内存(权重/内部/IO/命令流) │
│ ├── 权重转换 → native layout → 拷贝到 DMA 内存 │
│ └── 编译模型 → 生成命令流 + Task 数组 │
├──────────────────────────────────────────────────────────────────┤
│ 阶段 2:配置(可选) │
│ rknn_set_core_mask() → 选择 NPU 核心 │
│ rknn_register_custom_ops() → 注册自定义算子 │
│ rknn_set_input_shapes() → 设置动态 shape │
├──────────────────────────────────────────────────────────────────┤
│ 阶段 3:推理循环(可重复执行) │
│ rknn_inputs_set() → 格式/类型转换 → 拷贝到 DMA → flush cache │
│ rknn_run() → 构造 submit → ioctl(SUBMIT) → 等待中断 │
│ rknn_outputs_get() → invalidate cache → 反量化 → 格式转换 │
│ rknn_outputs_release() → 释放输出缓冲 │
├──────────────────────────────────────────────────────────────────┤
│ 阶段 4:销毁 │
│ rknn_destroy() │
│ ├── 释放所有 DMA 内存 │
│ ├── 关闭设备 fd │
│ └── 释放上下文 │
└──────────────────────────────────────────────────────────────────┘
二、阶段 1:初始化(rknn_init)
2.1 设备打开
rknn_init()
└── open("/dev/dri/card0") 或 open("/dev/dri/renderD128")
└── 获取 DRM fd
逆向证据:npu_interface.c 中 npu_open() 遍历 /dev/dri/card*,用 drmGetVersion() 检查驱动名是否为 "rknpu"。
2.2 硬件版本检查
struct rknpu_action action = { .flags = RKNPU_GET_HW_VERSION };
ioctl(fd, DRM_IOCTL_RKNPU_ACTION, &action);
// action.value → 硬件版本号
闭源库据此选择对应的硬件配置(核心数、CBUF 大小、支持的精度等)。
2.3 模型解析
.rknn 是 Rockchip 私有的模型格式,包含:
| 段 | 内容 | 说明 |
|---|---|---|
| 文件头 | 魔数、版本、段表 | 标识文件格式 |
| 网络拓扑 | 层定义、连接关系 | 计算图描述 |
| 权重数据 | 量化后的权重 | 可能已是 native layout |
| 预编译命令流 | 寄存器命令序列 | pre-compile 模型专用 |
| 量化参数 | scale/zp 表 | 每层或每通道 |
| 自定义字符串 | 用户元数据 | 可选 |
模型格式完全闭源,无公开文档。
2.4 内存分配
闭源库通过 ioctl 分配多块 DMA 内存:
ioctl(MEM_CREATE, { size, flags }) → { handle, obj_addr, dma_addr }
ioctl(MEM_MAP, { handle }) → { offset }
mmap(fd, offset) → virt_addr
分配的内存块:
| 用途 | flags | 说明 |
|---|---|---|
| 权重内存 | RKNPU_MEM_KERNEL_MAPPING | 内核态也需要访问 |
| 内部中间缓冲 | 0 或 RKNPU_MEM_CACHEABLE | 层间数据传递 |
| 输入缓冲 | 0 | 用户写入输入数据 |
| 输出缓冲 | 0 | 硬件写入输出数据 |
| 命令流缓冲(regcmd) | 0 | 存放 NPUOP 指令序列 |
| Task 数组 | RKNPU_MEM_KERNEL_MAPPING | 内核驱动直接读取 |
逆向证据:llama0.c 中 build_transformer() 分配了 regcmd(1024 字节)和 tasks(1024 字节,带 RKNPU_MEM_KERNEL_MAPPING)。
2.5 权重转换
闭源库将模型权重从存储格式转换为 NPU native layout:
原始权重(行主序)
↓ 量化(如果需要)
量化权重(INT8/INT4)
↓ 重排列
Native Layout(按硬件分块要求)
↓ memcpy
DMA 内存
逆向证据:llama0.c 中 create_weight_cache() 将 FP32 权重转为 FP16 并用 feature_data() 函数重排列到 native layout。
2.6 命令流编译
对于非预编译模型,闭源库为每层生成寄存器命令流:
网络层描述
↓ 参数计算
CNA/CORE/DPU 描述符
↓ NPUOP 编码
64-bit 命令序列(regcmd buffer)
↓
Task 数组(每个 task 指向一段命令流)
每条命令格式:NPUOP(模块ID, 寄存器值, 寄存器偏移)
// 编码:[15:0]=寄存器偏移, [47:16]=寄存器值, [63:48]=模块ID
#define NPUOP(op, value, reg) \
(((uint64_t)(op & 0xffff)) << 48) | \
(((uint64_t)(value & 0xffffffff)) << 16) | \
(uint64_t)(reg & 0xffff)
逆向证据:npu_matmul.c 中 gen_matmul_task() 生成 108 条 NPUOP 指令,覆盖 CNA(30 条)、CORE(6 条)、DPU(70+ 条)寄存器。
三、阶段 2:配置
3.1 核心选择
rknn_set_core_mask(ctx, RKNN_NPU_CORE_0_1_2);
影响后续 rknn_run() 中 rknpu_submit.core_mask 和 subcore_task[] 的填充。
多核切分逻辑(闭源库内部):
- 单核模式:所有 task 在一个核心上顺序执行
- 双核/三核模式:将 task 数组按层切分,分配到不同核心的
subcore_task[]
3.2 自定义算子注册
rknn_custom_op ops[1] = { ... };
rknn_register_custom_ops(ctx, ops, 1);
详见 自定义算子 API。
四、阶段 3:推理循环
4.1 设置输入(rknn_inputs_set)
rknn_input inputs[1];
inputs[0].index = 0;
inputs[0].buf = image_data;
inputs[0].size = 640 * 640 * 3;
inputs[0].type = RKNN_TENSOR_UINT8;
inputs[0].fmt = RKNN_TENSOR_NHWC;
inputs[0].pass_through = 0;
rknn_inputs_set(ctx, 1, inputs);
闭源库内部流程:
用户数据(NHWC, UINT8)
↓ pass_through == FALSE
格式转换: NHWC → NC1HWC2(NPU 原生格式)
↓
类型转换: UINT8 → INT8(应用 zp 偏移)
↓
memcpy → 输入 DMA 缓冲
↓
ioctl(MEM_SYNC, SYNC_TO_DEVICE) // flush CPU cache → 设备可见
如果 pass_through == TRUE,跳过格式/类型转换,直接拷贝。
4.2 执行推理(rknn_run)
rknn_run_extend extend = { .non_block = 0, .timeout_ms = 5000 };
rknn_run(ctx, &extend);
4.2.1 闭源库侧:构造 rknpu_submit
rknn_run()
├── 构造 rknpu_submit
│ ├── flags:
│ │ ├── RKNPU_JOB_PC (1) ← PC 模式
│ │ ├── RKNPU_JOB_BLOCK (0) ← 阻塞(或 NONBLOCK)
│ │ └── RKNPU_JOB_PINGPONG (4) ← 乒乓模式
│ ├── timeout = 5000
│ ├── task_start = 0
│ ├── task_number = N(总 task 数)
│ ├── task_obj_addr = tasks DMA 对象地址
│ ├── core_mask = 0x1(单核)或 0x7(三核)
│ └── subcore_task[]:
│ ├── [0] = { start=0, number=N } ← 核心 0 的 task 范围
│ ├── [1] = { start=N, number=0 } ← 核心 1(如果启用)
│ └── [2] = { start=N, number=0 } ← 核心 2(如果启用)
└── ioctl(DRM_IOCTL_RKNPU_SUBMIT, &submit)
4.2.2 内核驱动侧:任务提交完整时序
sequenceDiagram
participant U as 用户态 (librknnrt.so)
participant S as sys_ioctl
participant D as DeviceOps::ioctl
participant I as submit_ioctrl()
participant O as submit_one(idx)
participant P as submit_pc()
participant H as NPU 硬件
U->>S: ioctl(fd, DRM_IOCTL_RKNPU_SUBMIT, &rknpu_submit)
S->>D: dispatch by cmd
D->>I: submit_ioctrl(&submit_args)
Note over I: 解析 subcore_task[0..5]
loop idx = 0..4 (跳过 task_number == 0)
I->>O: submit_one(idx, args)
Note over O: 按 max_submit_number 分批
loop 每批 task
O->>P: submit_pc(batch_args)
Note over P: 1. 写 CNA.s_pointer / CORE.s_pointer
Note over P: 2. 写 PC.base_address = regcmd_base_addr
Note over P: 3. 写 PC.register_amounts
Note over P: 4. 写 PC.interrupt_mask / interrupt_clear
Note over P: 5. 写 PC.task_control (task_number + flags)
Note over P: 6. 写 PC.task_dma_base_addr
Note over P: 7. 写 GLOBAL.enable_mask
Note over P: 8. 写 PC.operation_enable = 1
Note over P: 9. 写 PC.operation_enable = 0
P->>H: 硬件开始执行命令流
loop 轮询等待
O->>H: 读 PC.interrupt_status
Note over O: status = rknpu_fuzz_status(raw_status)
alt status & int_mask != 0
H-->>O: 完成
else 未完成 & 未超时
Note over O: 继续轮询
else 超时
Note over O: 返回错误
end
end
O->>H: 写 PC.interrupt_clear = INT_CLEAR_ALL
Note over O: 写回最后一个 task 的 int_status
end
end
I-->>D: 返回结果
D-->>S: Ok / Err
S-->>U: ioctl 返回值
4.2.3 状态机
stateDiagram-v2
[*] --> IDLE: 驱动初始化完成
IDLE --> PARSING: 收到 SUBMIT ioctl
PARSING --> DISPATCHING: 解析 subcore_task[0..5]
DISPATCHING --> SUBMITTING: submit_one(idx)
Note right of DISPATCHING: 跳过 task_number == 0 的子核心
SUBMITTING --> HW_RUNNING: submit_pc() 写寄存器 + OP_EN=1
HW_RUNNING --> POLLING: 轮询 interrupt_status
POLLING --> COMPLETED: status & int_mask != 0
POLLING --> POLLING: 未完成 & 未超时
POLLING --> TIMEOUT: 超过 timeout
COMPLETED --> CLEARING: 写 interrupt_clear
CLEARING --> NEXT_BATCH: 还有剩余批次?
NEXT_BATCH --> SUBMITTING: 是,提交下一批
NEXT_BATCH --> NEXT_CORE: 否,当前子核心完成
NEXT_CORE --> DISPATCHING: 还有子核心?
NEXT_CORE --> DONE: 全部完成
DONE --> IDLE: 返回成功
TIMEOUT --> ERROR: 返回超时错误
ERROR --> IDLE: 错误恢复
4.2.4 解析 subcore_task[5]
rknpu_submit 包含 subcore_task[5],每个元素描述一个子核心要执行的 task 切片:
subcore_task[0]: { task_start: 0, task_number: 10 } → core 0 执行 task 0~9
subcore_task[1]: { task_start: 10, task_number: 5 } → core 1 执行 task 10~14
subcore_task[2]: { task_start: 15, task_number: 0 } → 跳过
subcore_task[3~4]: 跳过
驱动遍历 idx = 0..5,对 task_number > 0 的子核心调用 submit_one(idx, args)。
4.2.5 分批提交(max_submit_number)
每个子核心的 task 可能很多,但硬件一次能处理的 task 数量有上限(max_submit_number,取决于硬件版本)。因此 submit_one() 将 task 分批:
总 task_number = 100, max_submit_number = 12
批次 1: task[0..12] → submit_pc()
批次 2: task[12..24] → submit_pc()
...
批次 9: task[96..100] → submit_pc()
4.2.6 submit_pc() 寄存器写入序列
| 步骤 | 寄存器 | 写入值 | 说明 |
|---|---|---|---|
| 1 | CNA.s_pointer / CORE.s_pointer | 0xe + 0x10000000 * core_idx | 初始化子模块指针 |
| 2 | PC.base_address | regcmd_base_addr | 命令流 DMA 基址 |
| 3 | PC.register_amounts | 计算值 | 命令/寄存器项数量 |
| 4 | PC.interrupt_mask | task.int_mask | 设置期望的完成中断 |
| 5 | PC.interrupt_clear | task.int_clear | 清除残留中断 |
| 6 | PC.task_control | ((0x6 | pp_en) << bits) | task_num | 任务数量 + 控制位 |
| 7 | PC.task_dma_base_addr | task buffer DMA 地址 | task 描述符数组基址 |
| 8 | GLOBAL.enable_mask | task.enable_mask | 使能相关功能模块 |
| 9 | PC.operation_enable | 1 | 触发执行 |
| 10 | PC.operation_enable | 0 | 清边沿(脉冲触发) |
步骤 9→10 构成一个上升沿脉冲,硬件在检测到 OP_EN 从 0→1 时启动命令流执行。
4.2.7 等待完成与中断处理
Linux 内核驱动(中断驱动):
rknpu_irq_handler()
├── 读 INT_STATUS 寄存器
├── rknpu_fuzz_status() → 归一化中断状态
├── 写 INT_CLEAR → 清除中断
└── 唤醒 wait_queue / 信号 dma_fence
rknpu_job_done()
├── 写回 task[i].int_status
└── 信号 DMA fence / 唤醒用户态
StarryOS Rust 驱动(轮询模式):
loop {
raw_status = read(PC.interrupt_status)
status = rknpu_fuzz_status(raw_status)
if status & int_mask != 0 {
break // 完成
}
if elapsed > timeout {
return Error::Timeout
}
// 继续轮询(yield / sleep)
}
write(PC.interrupt_clear, INT_CLEAR_ALL) // 0x1ffff
// 写回最后一个 task 的 int_status
rknpu_fuzz_status():将每个模块的 2-bit 中断组归一化(任一非零 → 全置 1),确保与 int_mask 的比较不会因为硬件只置了部分 bit 而误判为未完成。
4.2.8 失败路径
超时:
| 触发条件 | 行为 | 恢复 |
|---|---|---|
轮询 interrupt_status 超过 submit.timeout 毫秒 | 返回超时错误 | 写 interrupt_clear = 0x1ffff,可能需要 NPU 软复位(ACTION::ACT_RESET) |
异常中断:
| 触发条件 | 说明 | 检测 |
|---|---|---|
DMA_RD_ERR (bit12) 或 DMA_WR_ERR (bit13) | DMA 读写错误(地址非法/IOMMU 映射缺失) | interrupt_status & 0x3000 |
非法参数:
| 参数 | 非法条件 | 行为 |
|---|---|---|
task_number | == 0(某个 subcore_task) | 跳过该子核心(非错误) |
core_mask | 无效核心选择 | 返回 EINVAL |
task_obj_addr | 无效内核对象地址 | 返回 EFAULT |
timeout | == 0 | 使用默认超时值 |
4.2.9 Linux 内核驱动 vs StarryOS 驱动差异
| 方面 | Linux rknpu 驱动 | StarryOS Rust 驱动 |
|---|---|---|
| 等待机制 | 中断驱动 + wait_queue + dma_fence | 轮询 interrupt_status |
| 多任务调度 | 内核 job 队列 + 优先级调度 | 串行提交 |
| fence 支持 | 完整 dma_fence + sync_file | 未实现 |
| IOMMU | RKIOMMU domain attach/detach | 未实现(物理连续内存) |
| 电源管理 | pm_runtime + devfreq | 直接寄存器操作(最小集) |
4.3 获取输出(rknn_outputs_get)
rknn_output outputs[3];
memset(outputs, 0, sizeof(outputs));
for (int i = 0; i < 3; i++) {
outputs[i].index = i;
outputs[i].want_float = 0;
}
rknn_outputs_get(ctx, 3, outputs, NULL);
闭源库内部流程:
rknn_outputs_get()
│
├── ioctl(MEM_SYNC, SYNC_FROM_DEVICE) // invalidate cache
│
├── 遍历 outputs[i]:
│ ├── 从输出 DMA 缓冲读取原始数据
│ ├── 如果 want_float:
│ │ ├── 反量化: INT8 → FP32(val = (qval - zp) * scale)
│ │ └── 格式转换: NC1HWC2 → NCHW/NHWC
│ ├── 如果 is_prealloc:
│ │ └── memcpy → 用户提供的 buf
│ └── 否则:
│ ├── malloc(size) → 分配 buf
│ └── memcpy → buf
│
└── 返回
4.4 释放输出
rknn_outputs_release(ctx, 3, outputs);
释放 rknn_outputs_get 中 is_prealloc == FALSE 时分配的 buf。
五、阶段 4:销毁(rknn_destroy)
rknn_destroy(ctx);
内部流程:
rknn_destroy()
├── 释放命令流缓冲
│ └── munmap() + ioctl(MEM_DESTROY)
├── 释放 Task 数组
│ └── munmap() + ioctl(MEM_DESTROY)
├── 释放权重内存
│ └── munmap() + ioctl(MEM_DESTROY)
├── 释放内部中间缓冲
│ └── munmap() + ioctl(MEM_DESTROY)
├── 释放输入/输出缓冲
│ └── munmap() + ioctl(MEM_DESTROY)
├── close(drm_fd)
└── free(context)
六、零拷贝推理路径
使用 RKNN_FLAG_MEM_ALLOC_OUTSIDE 时的高级路径:
// 1. 初始化(仅解析模型,不分配 IO 内存)
rknn_init(&ctx, model, size, RKNN_FLAG_MEM_ALLOC_OUTSIDE, NULL);
// 2. 查询内存需求
rknn_mem_size mem_size;
rknn_query(ctx, RKNN_QUERY_MEM_SIZE, &mem_size, sizeof(mem_size));
// 3. 用户分配内存
rknn_tensor_mem* weight_mem = rknn_create_mem(ctx, mem_size.total_weight_size);
rknn_tensor_mem* internal_mem = rknn_create_mem(ctx, mem_size.total_internal_size);
// 4. 绑定内存
rknn_set_weight_mem(ctx, weight_mem);
rknn_set_internal_mem(ctx, internal_mem);
// 5. 查询原生输入/输出属性
rknn_tensor_attr input_attr, output_attr;
input_attr.index = 0;
rknn_query(ctx, RKNN_QUERY_NATIVE_INPUT_ATTR, &input_attr, sizeof(input_attr));
// 6. 分配并绑定 IO 内存
rknn_tensor_mem* input_mem = rknn_create_mem(ctx, input_attr.size_with_stride);
rknn_set_io_mem(ctx, input_mem, &input_attr);
// 7. 直接写入 native layout 数据(无格式转换开销)
memcpy(input_mem->virt_addr, native_data, size);
// 8. 推理
rknn_run(ctx, NULL);
// 9. 直接读取输出(无拷贝)
float* output = (float*)output_mem->virt_addr;
此路径避免了 rknn_inputs_set 和 rknn_outputs_get 中的格式转换和数据拷贝。
七、异步推理路径
// 初始化时启用异步
rknn_init(&ctx, model, size, RKNN_FLAG_ASYNC_MASK, NULL);
// 帧 0
rknn_inputs_set(ctx, 1, inputs_frame0);
rknn_run(ctx, NULL);
// rknn_outputs_get 返回的是上一帧结果(第一次调用返回空)
rknn_outputs_get(ctx, n, outputs, NULL);
// 帧 1
rknn_inputs_set(ctx, 1, inputs_frame1);
rknn_run(ctx, NULL);
// 返回帧 0 的结果
rknn_outputs_get(ctx, n, outputs, NULL);
异步模式下 rknn_outputs_get 不等待当前帧完成,直接返回上一帧结果,提高单线程帧率。
八、DMA Fence 路径
// 初始化时启用 fence
rknn_init(&ctx, model, size,
RKNN_FLAG_FENCE_IN_OUTSIDE | RKNN_FLAG_FENCE_OUT_OUTSIDE, NULL);
// 推理时传入/获取 fence fd
rknn_run_extend extend;
extend.fence_fd = input_fence_fd; // 等待输入数据就绪
extend.non_block = 1;
rknn_run(ctx, &extend);
// extend.fence_fd 现在是输出 fence fd
// 可以传给 GPU/RGA 等下游设备
对应内核驱动的 RKNPU_JOB_FENCE_IN / RKNPU_JOB_FENCE_OUT 标志。
内存管理与零拷贝
闭源库的内存管理策略,包括 DMA 内存分配、cache 同步、零拷贝机制。
逆向来源:
rknn_api.h、rknpu_ioctl.h、npu_interface.c、llama0.c。
一、内存分配路径
1.1 闭源库内部分配
闭源库通过 DRM ioctl 分配 DMA 内存:
rknn_create_mem(ctx, size)
↓
ioctl(DRM_IOCTL_RKNPU_MEM_CREATE, {
.size = size,
.flags = flags
})
↓ 返回
{ handle, obj_addr, dma_addr }
↓
ioctl(DRM_IOCTL_RKNPU_MEM_MAP, { handle })
↓ 返回
{ offset }
↓
mmap(fd, size, offset)
↓ 返回
virt_addr
↓
填充 rknn_tensor_mem {
.virt_addr = virt_addr,
.phys_addr = dma_addr, // 实际是 IOVA
.fd = drm_fd,
.size = size,
.priv_data = 内部状态指针
}
1.2 内存类型标志
enum e_rknpu_mem_type {
RKNPU_MEM_CONTIGUOUS = 0 << 0, // 物理连续(默认)
RKNPU_MEM_NON_CONTIGUOUS = 1 << 0, // 物理不连续
RKNPU_MEM_NON_CACHEABLE = 0 << 1, // 不可缓存(默认)
RKNPU_MEM_CACHEABLE = 1 << 1, // 可缓存
RKNPU_MEM_WRITE_COMBINE = 1 << 2, // 写合并
RKNPU_MEM_KERNEL_MAPPING = 1 << 3, // 内核态映射
RKNPU_MEM_IOMMU = 1 << 4, // IOMMU 映射
RKNPU_MEM_ZEROING = 1 << 5, // 零初始化
RKNPU_MEM_SECURE = 1 << 6, // 安全缓冲
RKNPU_MEM_NON_DMA32 = 1 << 7, // 非 DMA32 区域
RKNPU_MEM_TRY_ALLOC_SRAM = 1 << 8, // 尝试 SRAM 分配
};
1.3 闭源库的内存分配策略
| 用途 | flags | 原因 |
|---|---|---|
| Task 数组 | KERNEL_MAPPING | 内核驱动需要直接读取 task 字段 |
| 命令流(regcmd) | 0 | 硬件通过 DMA 读取,不需要内核映射 |
| 权重 | KERNEL_MAPPING 或 0 | 取决于是否需要内核态访问 |
| 输入/输出 | 0 或 CACHEABLE | 用户频繁读写时用 CACHEABLE |
| 内部中间缓冲 | 0 | 仅硬件读写 |
逆向证据:bench_mark.c 中 tasks 用 RKNPU_MEM_KERNEL_MAPPING,其余用 0。
二、Cache 同步
2.1 同步模式
enum e_rknpu_mem_sync_mode {
RKNPU_MEM_SYNC_TO_DEVICE = 1 << 0, // CPU → 设备(flush)
RKNPU_MEM_SYNC_FROM_DEVICE = 1 << 1, // 设备 → CPU(invalidate)
};
2.2 同步时机
CPU 写入输入数据
↓
ioctl(MEM_SYNC, { flags=SYNC_TO_DEVICE, obj_addr, offset, size })
↓ flush CPU cache
NPU 可以安全读取
↓
NPU 执行完毕,写入输出
↓
ioctl(MEM_SYNC, { flags=SYNC_FROM_DEVICE, obj_addr, offset, size })
↓ invalidate CPU cache
CPU 可以安全读取输出
2.3 闭源库的 cache 优化标志
| 标志 | 效果 |
|---|---|
RKNN_FLAG_DISABLE_FLUSH_INPUT_MEM_CACHE | 跳过输入 flush(用户自行保证) |
RKNN_FLAG_DISABLE_FLUSH_OUTPUT_MEM_CACHE | 跳过输出 invalidate(输出由 GPU/RGA 消费) |
三、零拷贝机制
3.1 标准路径 vs 零拷贝路径
标准路径(rknn_inputs_set + rknn_outputs_get):
用户缓冲 → [格式转换] → [类型转换] → memcpy → DMA 缓冲 → NPU
NPU → DMA 缓冲 → memcpy → [反量化] → [格式转换] → 用户缓冲
至少 2 次 memcpy + 可能的格式/类型转换。
零拷贝路径(rknn_set_io_mem):
用户直接写入 DMA 缓冲(native layout)→ NPU
NPU → DMA 缓冲 → 用户直接读取
0 次 memcpy,但用户需要自行处理 native layout。
3.2 零拷贝 API
内部分配
rknn_tensor_mem* rknn_create_mem(rknn_context ctx, uint32_t size);
闭源库内部调用 ioctl(MEM_CREATE) + ioctl(MEM_MAP) + mmap()。
带标志分配
rknn_tensor_mem* rknn_create_mem2(rknn_context ctx, uint64_t size, uint64_t alloc_flags);
| alloc_flags | 说明 |
|---|---|
RKNN_FLAG_MEMORY_CACHEABLE | 可缓存内存 |
RKNN_FLAG_MEMORY_NON_CACHEABLE | 不可缓存内存 |
RKNN_FLAG_MEMORY_TRY_ALLOC_SRAM | 尝试 SRAM |
从外部 fd 创建
rknn_tensor_mem* rknn_create_mem_from_fd(rknn_context ctx,
int32_t fd, void* virt_addr, uint32_t size, int32_t offset);
用于导入其他设备(如 camera、GPU)分配的 DMA buffer。
从物理地址创建
rknn_tensor_mem* rknn_create_mem_from_phys(rknn_context ctx,
uint64_t phys_addr, void* virt_addr, uint32_t size);
从 mb_blk 创建
rknn_tensor_mem* rknn_create_mem_from_mb_blk(rknn_context ctx,
void* mb_blk, int32_t offset);
用于 Rockchip 多媒体框架的内存块。
销毁
int rknn_destroy_mem(rknn_context ctx, rknn_tensor_mem* mem);
逆向推断:内部根据 mem->flags 判断是否需要 munmap() 和 ioctl(MEM_DESTROY):
RKNN_TENSOR_MEMORY_FLAGS_ALLOC_INSIDE→ 完整释放RKNN_TENSOR_MEMORY_FLAGS_FROM_FD→ 仅释放包装结构RKNN_TENSOR_MEMORY_FLAGS_FROM_PHYS→ 仅释放包装结构
Cache 同步
int rknn_mem_sync(rknn_context context, rknn_tensor_mem* mem, rknn_mem_sync_mode mode);
| mode | 说明 |
|---|---|
RKNN_MEMORY_SYNC_TO_DEVICE | CPU 写完后调用 |
RKNN_MEMORY_SYNC_FROM_DEVICE | 读取设备输出前调用 |
RKNN_MEMORY_SYNC_BIDIRECTIONAL | 双向同步 |
逆向推断:内部调用 ioctl(DRM_IOCTL_RKNPU_MEM_SYNC, { flags, obj_addr, offset, size })。
3.3 IO 内存绑定
int rknn_set_io_mem(rknn_context ctx, rknn_tensor_mem* mem, rknn_tensor_attr* attr);
将用户分配的内存绑定为模型的输入或输出。attr->index 指定输入/输出索引。
int rknn_set_weight_mem(rknn_context ctx, rknn_tensor_mem* mem);
int rknn_set_internal_mem(rknn_context ctx, rknn_tensor_mem* mem);
绑定权重和内部内存。需配合 RKNN_FLAG_MEM_ALLOC_OUTSIDE 使用。
四、SRAM 管理
RK3588 NPU 有片上 SRAM,可用于减少 DDR 带宽:
// 查询 SRAM 大小
rknn_mem_size mem_size;
rknn_query(ctx, RKNN_QUERY_MEM_SIZE, &mem_size, sizeof(mem_size));
// mem_size.total_sram_size — 总 SRAM 大小
// mem_size.free_sram_size — 空闲 SRAM 大小
// 也可通过 ioctl 查询
struct rknpu_action action = { .flags = RKNPU_GET_TOTAL_SRAM_SIZE };
ioctl(fd, DRM_IOCTL_RKNPU_ACTION, &action);
启用 SRAM 分配:
- 初始化时设置
RKNN_FLAG_ENABLE_SRAM - 内存分配时使用
RKNPU_MEM_TRY_ALLOC_SRAM或RKNN_FLAG_MEMORY_TRY_ALLOC_SRAM
五、npu_llama 的 Buffer 池化策略
llama0.c 展示了一种用户态 buffer 池化方案,避免频繁的 DMA 内存分配/释放:
#define MAX_BUFFER_POOL_SIZE 8
typedef struct {
void* data;
uint64_t dma;
uint64_t obj;
uint32_t handle;
size_t size;
int in_use;
} NPUBuffer;
// 预分配不同大小的 buffer
size_t sizes[] = { 512KB, 1MB, 2MB, 512KB, 256KB, 256KB, 128KB, 128KB };
for (int i = 0; i < 8; i++) {
pool[i].data = mem_allocate(fd, sizes[i], &pool[i].dma, ...);
}
// 运行时从池中取用
NPUBuffer* buf = get_buffer_from_pool(t, required_size);
// ... 使用 buf->data / buf->dma ...
release_buffer_to_pool(buf);
闭源库内部很可能也使用类似的池化策略来管理内部中间缓冲。
闭源库内部机制
命令流生成、Task 构造、多核切分、数据格式转换等闭源库内部逻辑的逆向分析。
逆向来源:开源 demo
npu_matmul.c、bench_mark.c、llama0.c、内核驱动rknpu_job.c、StarryOS Rust 驱动。
一、命令流生成
1.1 命令流格式
每条命令是一个 64-bit 值,编码为:
63 48 47 16 15 0
┌────────────┬─────────────┬───────────┐
│ 模块 ID │ 寄存器值 │ 寄存器偏移 │
│ (16-bit) │ (32-bit) │ (16-bit) │
└────────────┴─────────────┴───────────┘
#define NPUOP(op, value, reg) \
(((uint64_t)(op & 0xffff)) << 48) | \
(((uint64_t)(value & 0xffffffff)) << 16) | \
(uint64_t)(reg & 0xffff)
1.2 模块 ID 编码
#define BLOCK_PC 0x0100
#define BLOCK_CNA 0x0200
#define BLOCK_CORE 0x0800
#define BLOCK_DPU 0x1000
#define BLOCK_DPU_RDMA 0x2000
#define BLOCK_PPU 0x4000
#define BLOCK_PPU_RDMA 0x8000
#define PC_OP_01 0x01 // 寄存器写入标志
#define PC_OP_40 0x40 // 未知用途
#define PC_OP_ENABLE 0x80 // 使能标志
#define OP_REG_CNA (BLOCK_CNA | PC_OP_01) // 0x0201
#define OP_REG_CORE (BLOCK_CORE | PC_OP_01) // 0x0801
#define OP_REG_DPU (BLOCK_DPU | PC_OP_01) // 0x1001
#define OP_ENABLE (PC_OP_ENABLE | PC_OP_01) // 0x0081
1.3 命令流结构(以 matmul 为例)
一个典型的 CNA→CORE→DPU 流水线命令流包含约 108 条指令:
ops[0] DPU_S_POINTER = 0xE ← DPU 寄存器组指针
ops[1~28] CNA 寄存器(卷积参数) ← 28 条
ops[29~40] CNA 权重解压缩寄存器 ← 12 条
ops[41~42] CNA 补充寄存器 ← 2 条
ops[43] CNA_S_POINTER = 0xE ← CNA 寄存器组指针
ops[44~49] CORE 寄存器 ← 6 条
ops[50] CORE_S_POINTER = 0xE ← CORE 寄存器组指针
ops[51~106] DPU 寄存器(后处理参数) ← 56 条
ops[107] PC_OPERATION_ENABLE ← 全局使能
最后一条指令触发硬件开始执行:
ops[107] = NPUOP(OP_ENABLE,
PC_ENABLE_DPU | PC_ENABLE_CNA | PC_ENABLE, // 0x0d
PC_OPERATION_ENABLE); // 0x0008
1.4 S_POINTER 寄存器
每个模块有一个 S_POINTER 寄存器(偏移 0x_004),用于切换寄存器组(乒乓机制):
ops[0] = NPUOP(OP_REG_DPU, 0xE, DPU_S_POINTER); // 0x4004
ops[43] = NPUOP(OP_REG_CNA, 0xE, CNA_S_POINTER); // 0x1004
ops[50] = NPUOP(OP_REG_CORE, 0xE, CORE_S_POINTER); // 0x3004
值 0xE 的含义尚未完全逆向,推测与寄存器组选择和同步有关。
二、CNA 参数填充
CNA(Convolution Neural-network Accelerator)负责卷积计算的数据加载和 MAC 阵列控制。
2.1 CNA 描述符
typedef struct npu_cna_desc {
uint8_t conv_mode; // 卷积模式(0=direct)
uint8_t in_precision; // 输入精度(0=INT8, 2=FP16)
uint8_t proc_precision; // 处理精度
uint8_t kernel_groups; // 权重分组数
uint16_t feature_grains; // 特征粒度
uint8_t conv_x_stride; // X 方向步长
uint8_t conv_y_stride; // Y 方向步长
uint16_t datain_width; // 输入宽度
uint16_t datain_height; // 输入高度
uint16_t datain_channel; // 输入通道数
uint16_t dataout_width; // 输出宽度
uint32_t dataout_atomics; // 输出原子数
uint32_t weight_bytes; // 权重总字节数
uint32_t weight_bytes_per_kernel; // 每个 kernel 的权重字节数
uint8_t weight_width; // 权重宽度
uint8_t weight_height; // 权重高度
uint16_t weight_kernels; // 权重 kernel 数
uint8_t weight_bank; // 权重 CBUF bank 数
uint8_t data_bank; // 数据 CBUF bank 数
uint16_t data_entries; // 数据 CBUF 条目数
uint32_t feature_base_addr; // 特征数据 DMA 基地址
uint32_t line_stride; // 行步长
int32_t surf_stride; // 面步长
// ... 更多字段
} npu_cna_desc;
2.2 CBUF Bank 分配
CBUF 是 CNA 内部的片上缓冲,共 12 个 bank,每个 32KB:
#define NPU_CBUF_BANK_SIZE 32768 // 32KB
#define NPU_CBUF_BANKS 12
// 分配策略(从 gen_matmul_fp16 逆向):
int weight_banks = ceil(weight_bytes / NPU_CBUF_BANK_SIZE);
int data_banks = NPU_CBUF_BANKS - weight_banks;
// 确保 data_banks >= 1
闭源库需要为每层计算最优的 bank 分配,平衡权重和数据的缓存需求。
2.3 Matmul → 卷积映射
NPU 没有专用的 matmul 单元,矩阵乘法通过卷积实现:
矩阵乘法 C[M×N] = A[M×K] × B[K×N]
↓ 映射为
1×1 卷积:
输入特征: A 重排为 [M, K, 1, 1](M 个样本,K 通道)
权重: B 重排为 [N, K, 1, 1](N 个 1×1 kernel,K 通道)
输出: C 为 [M, N, 1, 1]
逆向证据:gen_matmul_fp16() 中设置 conv_mode = direct_convolution,weight_width = weight_height = 1,conv_x_stride = conv_y_stride = 1。
三、DPU 参数填充
DPU(Data Processing Unit)负责后处理:BS(Bias/Scale)、BN(Batch Norm)、EW(Element-wise)、LUT(激活函数)、输出转换。
3.1 DPU 描述符
typedef struct npu_dpu_desc {
uint8_t flying_mode; // 0=on-flying(从 CORE 直接接收)
uint8_t output_mode; // 输出模式
uint8_t conv_mode; // 卷积模式
uint8_t out_precision; // 输出精度
uint8_t in_precision; // 输入精度
uint8_t proc_precision; // 处理精度
uint32_t dst_base_addr; // 输出 DMA 基地址
uint32_t dst_surf_stride; // 输出面步长
uint16_t width, height; // 输出尺寸
uint16_t channel; // 输出通道
// BS 旁路控制
uint8_t bs_bypass; // 1=旁路 BS
uint8_t bs_alu_bypass; // 1=旁路 BS ALU
uint8_t bs_mul_bypass; // 1=旁路 BS MUL
uint8_t bs_relu_bypass; // 1=旁路 BS ReLU
// BN 旁路控制
uint8_t bn_bypass;
uint8_t bn_alu_bypass;
uint8_t bn_mul_bypass;
uint8_t bn_relu_bypass;
// EW 旁路控制
uint8_t ew_bypass;
uint8_t ew_op_bypass;
uint8_t ew_lut_bypass;
uint8_t ew_op_cvt_bypass;
uint8_t ew_relu_bypass;
// 输出转换
uint8_t fp32tofp16_en; // FP32→FP16 使能
uint16_t out_cvt_scale; // 输出缩放因子
uint32_t surf_add; // 面地址增量
} npu_dpu_desc;
3.2 旁路模式
对于简单的 matmul,DPU 大部分功能被旁路:
// gen_matmul_task() 中的典型设置:
dpu_desc.bs_bypass = 1; // 无 bias
dpu_desc.bs_alu_bypass = 1;
dpu_desc.bs_mul_bypass = 1;
dpu_desc.bs_relu_bypass = 1;
dpu_desc.bn_bypass = 1; // 无 batch norm
dpu_desc.bn_alu_bypass = 1;
dpu_desc.bn_mul_bypass = 1;
dpu_desc.bn_relu_bypass = 1;
dpu_desc.ew_bypass = 1; // 无 element-wise
dpu_desc.ew_op_bypass = 1;
dpu_desc.ew_lut_bypass = 1;
dpu_desc.ew_op_cvt_bypass = 1;
dpu_desc.ew_relu_bypass = 1;
闭源库在编译复杂模型时,会根据每层的算子类型选择性启用这些功能。
四、Task 构造
4.1 Task 结构
struct rknpu_task {
uint32_t flags; // 任务标志
uint32_t op_idx; // 算子索引
uint32_t enable_mask; // 模块使能掩码
uint32_t int_mask; // 期望的中断掩码
uint32_t int_clear; // 中断清除值
uint32_t int_status; // [内核写回] 实际中断状态
uint32_t regcfg_amount; // 命令流中的指令数量
uint32_t regcfg_offset; // 命令流偏移(字节)
uint64_t regcmd_addr; // 命令流 DMA 地址
};
4.2 关键字段计算
enable_mask(偏移 0xF008):
#define PC_ENABLE 0x01 // 全局使能
#define PC_ENABLE_CNA 0x04 // CNA 中断使能
#define PC_ENABLE_DPU 0x08 // DPU 中断使能
#define PC_ENABLE_PPU 0x10 // PPU 中断使能
// CNA + CORE + DPU 流水线:
enable_mask = PC_ENABLE | PC_ENABLE_CNA | PC_ENABLE_DPU; // 0x0d
int_mask(偏移 0x0020):
// 中断位定义(从内核驱动 rknpu_ioctl.h 推断):
// bit[8] = DPU group 0 完成
// bit[9] = DPU group 1 完成
// 对于单 task matmul:
int_mask = 0x300; // 等待 DPU group 0 和 group 1 完成
int_clear:
int_clear = 0x1ffff; // 清除所有 17 位中断
regcfg_amount:
// 命令流指令数 - 额外保留量 - 尾部保留
regcfg_amount = total_ops - RKNPU_PC_DATA_EXTRA_AMOUNT - 4;
// RKNPU_PC_DATA_EXTRA_AMOUNT = 4(内核驱动会额外加回)
逆向证据:内核驱动 rknpu_job_subcore_commit_pc() 中:
amount = task->regcfg_amount + rknpu->config->pc_data_extra_amount;
4.3 多 Task 场景
对于多层网络,闭源库生成多个 task,每个 task 对应一层或一组层:
Task[0]: 第 1 层卷积(CNA+CORE+DPU)
regcmd_addr → 命令流偏移 0
regcfg_amount = 108
Task[1]: 第 2 层卷积
regcmd_addr → 命令流偏移 108*8
regcfg_amount = 108
...
Task[N-1]: 最后一层
五、多核切分
5.1 Submit 结构
struct rknpu_submit {
uint32_t flags;
uint32_t timeout;
uint32_t task_start;
uint32_t task_number; // 总 task 数
uint32_t core_mask; // 使用的核心掩码
struct rknpu_subcore_task subcore_task[5]; // 每核心的 task 范围
};
struct rknpu_subcore_task {
uint32_t task_start; // 起始 task 索引
uint32_t task_number; // task 数量
};
5.2 单核模式
submit.core_mask = 0x1; // 仅核心 0
submit.subcore_task[0] = { .task_start = 0, .task_number = N };
submit.subcore_task[1] = { .task_start = N, .task_number = 0 }; // 哨兵
submit.subcore_task[2] = { .task_start = N, .task_number = 0 };
逆向证据:bench_mark.c 和 llama0.c 均使用此模式。
5.3 多核模式(闭源库独有)
闭源库将 task 数组切分到多个核心:
假设 12 个 task,3 核心模式:
submit.core_mask = 0x7; // 核心 0+1+2
submit.subcore_task[0] = { 0, 4 }; // 核心 0: task 0~3
submit.subcore_task[1] = { 4, 4 }; // 核心 1: task 4~7
submit.subcore_task[2] = { 8, 4 }; // 核心 2: task 8~11
切分策略是闭源库的核心竞争力之一,涉及:
- 层间数据依赖分析
- 计算量均衡
- 内存带宽分配
- CBUF 冲突避免
5.4 乒乓模式
RKNPU_JOB_PINGPONG 标志启用硬件乒乓机制:
Task[0] 在 group 0 执行
↓ 完成,触发 group 0 中断
Task[1] 在 group 1 执行(与 Task[0] 的 DPU 输出重叠)
↓ 完成,触发 group 1 中断
Task[2] 在 group 0 执行
...
这允许流水线执行:当 Task[N] 在 DPU 阶段输出时,Task[N+1] 已经在 CNA 阶段加载数据。
六、数据格式转换
6.1 特征数据排列(feature_data)
从 npu_matmul.h 导出的函数,将行主序坐标转换为 NPU native layout 索引:
int feature_data(int C, int H, int W, int C2, int c, int h, int w);
| 参数 | 说明 |
|---|---|
| C | 通道总数 |
| H | 高度 |
| W | 宽度 |
| C2 | 通道分组大小(FP16=8, INT8=16, FP32=4) |
| c, h, w | 1-indexed 坐标 |
逆向推断的公式:
native_index = (c-1)/C2 * (H*W*C2) + (h-1)*W*C2 + (w-1)*C2 + (c-1)%C2
这对应 NC1HWC2 格式:(N, ceil(C/C2), H, W, C2)。
6.2 权重排列
FP16 权重(weight_fp16)
int weight_fp16(int C, int k, int c);
| 参数 | 说明 |
|---|---|
| C | 输入通道数(K 维度) |
| k | kernel 索引(1-indexed) |
| c | 通道索引(1-indexed) |
对应 native layout (N/16, K/32, 16, 32) 的 FP16 变体。
INT8 权重(weight_int8)
int weight_int8(int C, int k, int c);
对应 native layout (N/32, K/32, 32, 32)。
6.3 闭源库的格式转换链
用户输入(NHWC, UINT8)
↓ rknn_inputs_set()
├── NHWC → NCHW(如果模型需要)
├── UINT8 → INT8(减去 zp)
└── NCHW → NC1HWC2(NPU native)
↓
NPU 执行
↓
NPU 输出(NC1HWC2, INT8/FP16)
↓ rknn_outputs_get()
├── NC1HWC2 → NCHW/NHWC
├── INT8 → FP32((val - zp) * scale)
└── 拷贝到用户缓冲
零拷贝路径跳过所有转换,用户直接操作 native layout。
七、闭源库 vs 裸 ioctl 对照表
| 闭源库内部操作 | 裸 ioctl demo 对应 | 文件 |
|---|---|---|
| 模型解析 | 无(用户手动定义参数) | — |
| CNA 描述符填充 | gen_matmul_fp16() | npu_matmul.c |
| DPU 描述符填充 | gen_matmul_task() | npu_matmul.c |
| NPUOP 编码 | NPUOP() 宏 | npu_hw.h |
| Task 构造 | 手动填充 tasks[0] | bench_mark.c |
| Submit 构造 | 手动填充 submit | bench_mark.c |
| 权重转换 | weight_fp16() / weight_int8() | npu_matmul.c |
| 特征排列 | feature_data() | npu_matmul.c |
| 内存分配 | mem_allocate() | npu_interface.c |
| 内存释放 | mem_destroy() | npu_interface.c |
| 设备打开 | npu_open() | npu_interface.c |
| 设备复位 | npu_reset() | npu_interface.c |
| Buffer 池化 | NPUBuffer 池 | llama0.c |
| 权重缓存 | NPUWeightCache | llama0.c |